计网期末复习之应用层
1、网络应用程序部署
(1)部署在端系统上(2)没有应用程序软件运行在网络核心设备上
2、网络应用程序体系结构
(1)C/S体系结构 Server:具有固定的、众所周知的IP地址;总是打开的主机;主机群集; Client:可以间断的同服务器连接;拥有动态IP地址;客户机相互之间不直接通信
(2)P2P体系结构 没有总是打开的服务器;任意一对主机直接相互通信;对等方间歇连接并且可以改变IP地址;自扩展性;难以管理
(3)C/S和P2P混合的体系结构 中心服务器记录对等方内容(用户注册、文件存储信息等),供用户搜索;
3、进程通信
(1)同一主机上运行的进程之间进程间通信机制进行通信,由操作系统提供。
(2)不同主机上运行的进程间交换报文进行通信。进程间通信利用socket发送/接收消息实现。
具有P2P体系结构的应用程序既有客户进程(发起通信的进程)和服务器进程(发起通信的进程)。
4、如何寻址进程?
(1)不同主机上的进程间通信,那么每个进程必须拥有标识符( IP地址、端口号)(2)常用网络程序的端口号:Web服务:80;邮件服务:25
5、常见应用的传输服务需求
| 应用 | 数据丢失 | 带宽 | 时间敏感 |
|---|---|---|---|
| 文件传输 | 不能丢失 | 弹性 | 不 |
| 电子邮件 | 不能丢失 | 弹性 | 不 |
| Web | 不能丢失 | 弹性 | 不 |
| 实时音频/视频 | 容忍丢失 | 音频: 几kbps-1Mbps | 是,100 msec |
| 存储音频/视频 | 容忍丢失 | 视频:10kbps-5Mbps | 是, 几秒 |
| 交互式游戏 | 容忍丢失 | 视频:10kbps-5Mbps | 是, 100 msec |
| 即时讯息 | 不能丢失 | 几 kbps 以上 ,弹性 | 是和不是 |
6、因特网运输层提供的服务
(1)TCP服务:面向连接、可靠数据传输、流量控制、拥塞控制;无时延和带宽保证
(2)UDP服务:不提供建立连接,可靠性,流量控制,拥塞控制,时延和带宽保证。
面向连接:必须在建立连接前确认双方链路可达,并已准备好才开始通信,提供可靠或者不可靠的服务。
无连接:发送端在开始通信前不去询问接收端是否可达和是否已准备好接收数据,提供不可靠的服务。
7、因特网应用:应用层协议,传输协议
| 应用 | 应用层协议 | 下面的传输协议 |
|---|---|---|
| 电子邮件 | SMTP [RFC 2821] | TCP |
| 远程终端访问 | Telnet [RFC 854] | TCP |
| Web | HTTP [RFC 2616] | TCP |
| 文件传输 | FTP [RFC 959] | TCP |
| 流媒体 | 通常专用(e.g. RealNetworks) | TCP or UDP |
| 因特网电话 | 通常专用(e.g., Skype) | 典型用 UDP |
8、网页(Web页,或称文档)由许多对象组成,每个对象被一个URL(Uniform Resource Locator统一资源定位符)寻址(协议名、主机名、路径名)。多数网页由单个基本HTML文件和若干个所引用的对象构成。
比如:http://www.someschool.edu/someDept/pic.gif
9、HTTP: 超文本传输协议(Web的应用层协议)
(1)client/server模式:客户端浏览器请求+ Web服务器响应
(2)工作过程:
- 客户初始化一个与HTTP服务器80端口的TCP连接 (创建套接字)
- HTTP服务器接受来自客户的TCP连接请求, 建立连接
- Browser (HTTP client)和Web服务器 (HTTP server) 交换HTTP消息(应用层协议消息)包括HTTP请求和响应消息
- 最后结束(或叫关闭)TCP连接
(3)HTTP是一个无状态的协议:HTTP服务器不维护客户先前的状态信息
10、HTTP持久连接和非持久连接
非持久HTTP连接:每个TCP连接上只传送一个对象,下载多个对象需要建立多个TCP连接,HTTP/1.0使用非持久HTTP连接
持久HTTP连接:一个TCP连接上可以传送多个对象,HTTP/1.1默认使用持久HTTP连接
例:假设该页面含有一个HTML基本文件和10个JPEG图形, 并且这11个对象位于同一台服务器上。
进一步假设该HTML文件的URL为:http://www.someSchool.edu/someDepartment/home.index
(1) HTTP客户进程在端口号80发起一个到服务器 www.someSchool.edu 的TCP连接,该端口号是HTTP的默认端口。在客户和服务器上分别有一个套接字与该连接相关联。
(2) HTTP客户经它的套接字向该服务器发送一个HTTP请求报文。请求报文中包含了路径名/someDepartment/home.index。
(3) HTTP服务器进程经它的套接字接收该请求报文,从其存储器(RAM或磁盘)中检索出对象 www.someSchool.edu/someDepartment/home.index ,在一个HTTP响应报文中封装对象,并通过其套接字向客户发送响应报文。
(4)HTTP服务器进程通知TCP断开该TCP连接。
(5)HTTP客户接收响应报文,TCP连接关闭。该报文指出封装的对象件,客户从响应报文中提取出该文件,检查该HTML文件,得到对10个JPEG图形的引用。
(6) 对每个引用的JPEG图形对象重复前4个步骤。
不带流水线的持久HTTP连接:客户先前响应消息收到,才发出新的请求消息,每个引用对象经历1个RTT
**带流水线的持久HTTP连接 **:HTTP/1.1默认使用客户遇到1个引用对象就发送请求消息,所有引用对象只经历1个RTT
11、HTTP报文格式:请求报文request, 响应报文response(常见命令和状态码)

假设有HTTP请求报文:
GET /somedir/page.html HTTP/1.1
其中,/somedir/page.html被称为()URI 或Uniform Resource Identifiers 或统一资源标识符
HTTP/1.0
- GET
- POST
- HEAD
- 服务器收到请求时,用HTTP报文进行响应,但不返回请求对象
HTTP/1.1
GET, POST, HEAD
PUT
- 文件在实体主体中被上载到URL字段指定的路径
DELETE
- 删除URL字段指定的文件
上载表单(各字段)输入值
Post方法:网页时常包含表单输入,输入值在请求报文的实体主体中被上载到服务器
URL方法:使用GET方法,表单(各字段)输入值被上载,以URL请求行的字段: www.somesite.com/animalsearch?monkeys&banana


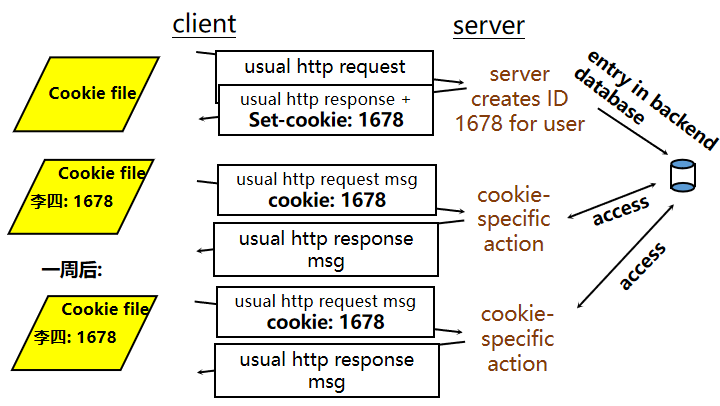
12、 Cookies作用,如何实现
(1)Cookies: 跟踪用户,提高用户和服务器的交互性
(2)cookie头部行在HTTP请求消息(或响应消息)中
(3)cookie文件 保存在用户主机中并被用户浏览器管理
(4)cookie也保存在Web站点的后端数据库
(5)应用场景:身份认证/虚拟购物车/推荐广告/用户会话状态
(6)优点:cookies允许网站更加了解你,你可以提供名字和e-mail给网站 ,广告公司通过网站获得信息,Cookies不适合游动用户
13、Web 缓存 (代理服务器),如何实现,条件GET方法
目标:在不访问服务器的前提下满足客户端的HTTP请求。
Web缓存/代理服务器
用户设定浏览器通过缓存进行Web访问
浏览器向缓存/代理服务器发送所有的HTTP请求
- 如果所请求对象在缓存中,缓存器返回对象
- 否则缓存器向起始服务器发出请求,接收对象后转发给客户机
缓存既充当客户端,也充当服务器
一般由ISP(Internet服务提供商)架设

为什么需要Web缓存器?
减少对客户机请求的响应时间
减少内部网络与接入链路上的通信量
能从整体上大大降低因特网上的Web流量
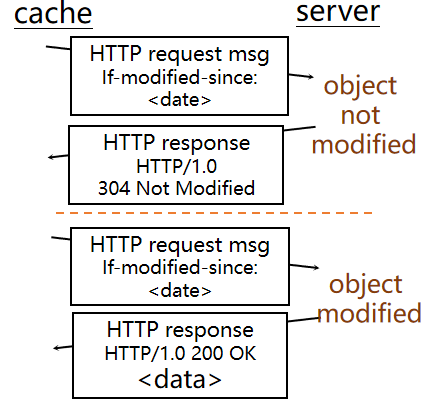
条件GET方法
目的: 证实缓存器中的对象是否为最新
缓存器:在请求报文中包含对象最后修改时间 If-modified-since: <date>
服务器: 如果对象是最新的则响应报文中不包含对象: HTTP/1.0 304 Not Modified
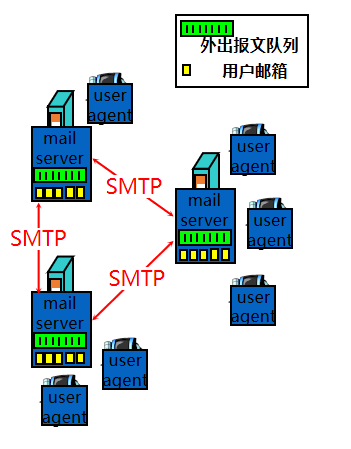
14、用户代理user agents、邮件服务器mail servers、简单邮件传送协议和邮件接收协议的作用
用户代理:
允许用户阅读,回复,转发,保存,编辑邮件消息
发送, 接收邮件消息到/从服务器
邮件服务器
- 邮箱mailbox存放用户接收的邮件消息
- 外出报文队列outgoing message queue
SMTP协议
运行邮件服务器之间传递消息所使用的协议
客户端:发送消息的服务器
服务器:接收消息的服务器
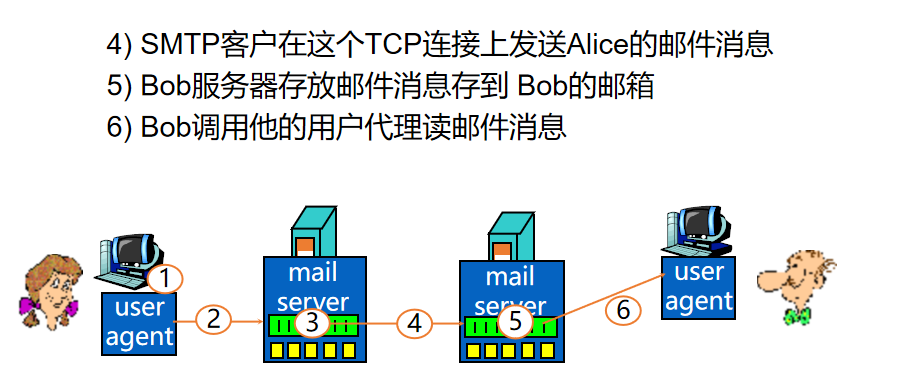
15、电子邮件协议(SMTP/POP3、IMAP、HTTP)各自端口号
SMTP
- 客户使用TCP来可靠传输邮件消息到服务器端口号25
- 传输的3个阶段:握手 (问候)、邮件消息的传输、结束
- 发送服务器到接收服务器采用直接传送
- 使用持久连接
- 命令/应答的交互,服务器使用CRLF.CRLF 来判断邮件消息的结束
- 命令: ASCII文本格式
- 应答: 状态码及其短语
- 邮件消息必须是7-bit ASCII
- 与HTTP协议比较
- HTTP是拉协议(把信息拉下来),SMTP是推协议(把信息送出去)
- HTTP的每个对象封装在它各自的HTTP响应消息中发送;SMTP一个邮件内各个对象置于同一个邮件消息的多目部分发送



POP3
Post Office Protocol 邮局协议[RFC 1939]110端口号
身份认证 (代理 <–>服务器)
客户命令:
- user username
- pass password
服务器响应
- +OK
- -ERR
下载邮件消息
- list: 列出邮件编号
- retr: 按编号取邮件
- dele: 删除
- quit
POP3的会话是无状态的
IMAP
- 所有邮件消息保存在一个位置: 服务器
- 允许用户利用文件夹组织管理邮件消息
- IMAP支持跨会话(Session)的用户状态:
- 文件夹的名字
- 邮件消息IDs和文件夹的映射
16、DNS的功能、特点
DNS服务器提供的功能:
主机名到IP地址的转换
主机别名:一个主机可以有一个规范主机名和多个主机别名
邮件服务器别名
负载分配
- DNS实现冗余服务器:一个IP地址集合可以对应于同一个规范主机名。
DNS(Domain Name System:域名系统)特点
- 分布式数据库:一个由分层DNS服务器实现的分布式数据库
- 应用层协议:DNS服务器实现域名转换 (域名/地址转换)
为什么不集中式DNS?
单点故障
巨大访问量
远距离集中式数据库
维护
不可扩展!
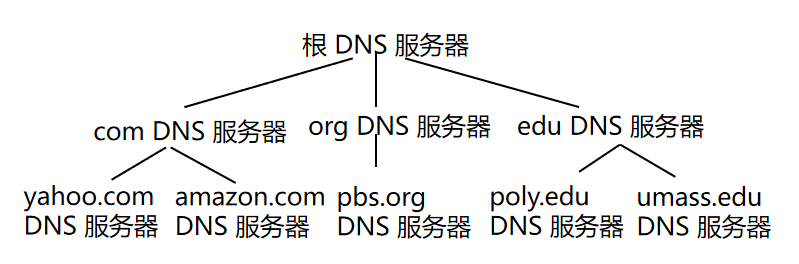
客户机怎样决定主机名www.amazon.com 的IP地址?
客户机查询根服务器得到com DNS服务器
客户机查询com DNS服务器得到amazon.comDNS服务器
客户机查询amazon.comDNS服务器得到www.amazon.com 的IP地址
顶级域服务器(top-level domain servers):负责顶级域名 com, org, net, edu, etc(用途域名或者类别域名), 和所有国家的顶级域名 uk, fr, ca, jp.
权威DNS服务器(authoritative DNS servers): 在因特网上具有公共可访问主机(如Web服务器和邮件服务器)的每个组织机构必须提供公共可访问的DNS记录,这些记录将这些主机的名字映射为IP地址。组织机构的权威DNS服务器负责保存这些DNS记录。多数大学和公司维护它们的基本权威DNS服务器
本地DNS服务器(Local DNS name server)
- 严格来说不属于该服务器的层次结构
- 每个ISP(如居民区ISP、公司、大学)都有一个本地DNS,也叫默认服务器
- 当主机发出DNS请求时,该请求被发往本地DNS服务器。起着代理的作用,转发请求到层次结构中
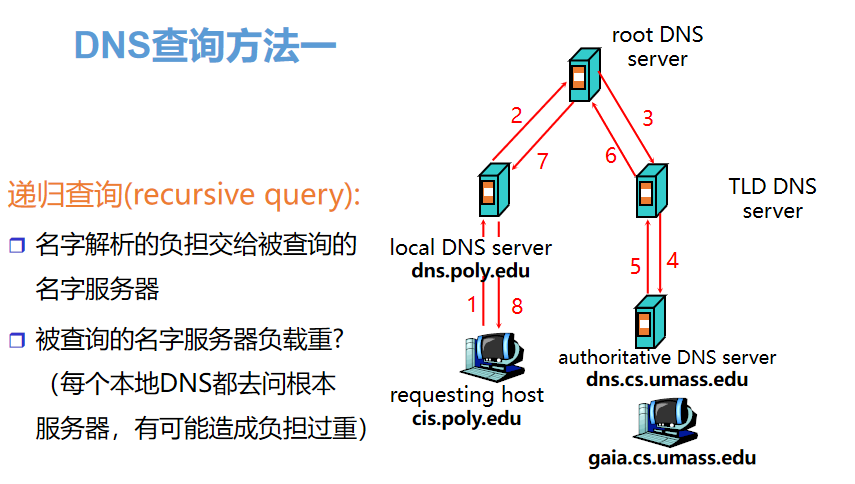
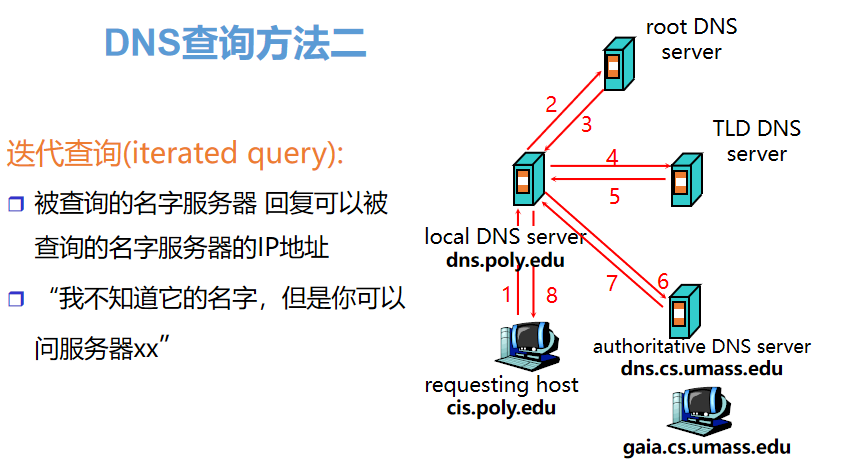
17、DNS的查询方法
问题:Cis.poly.edu的主机想获得gaia.cs.umass.edu的IP地址
 假设用一个全新的浏览器(第一次启动的那种),访问百度(http://www.baidu.com/ ),在敲入网址并按下回车之后:
假设用一个全新的浏览器(第一次启动的那种),访问百度(http://www.baidu.com/ ),在敲入网址并按下回车之后:
1、获得IP地址
(1)首先搜索浏览器的 DNS 缓存,缓存中维护一张域名与 IP 地址的对应表(2)若没有命中,则继续搜索操作系统的 DNS 缓存(Linux,/etc/hosts; Windows, C:\WINDOWS\system32\drivers\etc\hosts)
(3)若仍然没有命中,则操作系统将域名发送至本地域名服务器,本地域名服务器采用递归查询自己的 DNS 缓存,查找成功则返回结果
(4)若本地域名服务器的 DNS 缓存没有命中,则本地域名服务器向上级域名服务器进行迭代查询
本地域名服务器向根域名服务器发起请求,根域名服务器返回顶级域名服务器地址给本地服务器
本地域名服务器拿到顶级域名服务器地址后,向其发起请求,获取权威域名服务器地址
本地域名服务器根据权威域名服务器地址,向其发起请求,得到该域名对应的 IP 地址
本地域名服务器将得到的 IP 地址返回给操作系统,同时自己将 IP 地址缓存起来
(5)操作系统将 IP 地址返回给浏览器,同时自己也将 IP 地址缓存。浏览器得到域名对应的 IP 地址,并将 IP 地址缓存(缓存时间)。
2、和起始服务器(或者Web缓存/代理服务器),建立TCP连接 得到百度的IP,下一步是使用TCP协议,建立TCP连接。
3、向起始服务器(或者Web缓存/代理服务器)发送请求报文,用HTTP协议请求网页内容
4、浏览器收到响应报文,并解析。
18、DNS记录,创建一个“网络乌托邦”公司,如何搭建权威服务器
DNS: 存储资源记录(RR,Resource Records)的分布式数据库
RR 格式: (name, value, type,ttl)
Type=A(Address)
- name = 主机名
- value = IP地址
Type=CNAME(canonical)
name = 主机别名
www.ibm.com 的真名为 servereast.backup2.ibm.com
value = 真实的规范主机名
Type=NS( name server )
- name = 域名(如foo.com)
- value = 该域权威名字服务器的主机名
Type=MX(mail exchange)
- name =邮件服务器的主机别名
- value =邮件服务器的真实规范主机名
例子:刚刚创建一个“网络乌托邦”公司
在域名管理机构(如Network Solutions)注册域名networkutopia.com
- 需要提供你自己的基本权威DNS服务器的名字和IP地址
- 该注册登记机构将下列两条资源记录插入注册机构的DNS系统中:
- (networkutopia.com, dns1.networkutopia.com,NS)
- (dns1.networkutopia.com, 212.212.212.1, A)
在权威域名解析服务器中为www.networkuptopia.com (真实机器名web1. networkuptopia.com, IP地址212.212.212.2)加入Type A记录,为mail.networkutopia.com(真实机器名mx1.mxmail. networkuptopia.com,IP地址212.212.212.3)加入Type MX记录
- ( www.networkuptopia.com , web1. networkuptopia.com,CNAME)
- (web1. networkuptopia.com,212.212.212.2, A)
- ( mail.networkutopia.com, mx1.mxmail. networkuptopia.com, MX)
- (mx1.mxmail. networkuptopia.com,212.212.212.3,A)
网站主机名是www.foo.com , 真实的规范主机名是servereast.backup1.foo.com,IP地址:112.147.11.30。邮件主机名mail.foo.com,真实的规范主机名servereast.backup2.foo.com,IP地址:112.147.11.40。在权威服务器中需要的RR?
- (www.foo.com , servereast.backup1.foo.com, CNAME)
- (servereast.backup1.foo.com ,12.147.11.30, A )
- (mail.foo.com, servereast.backup2.foo.com, MX )
- (servereast.backup2.foo.com, 112.147.11.40, A)
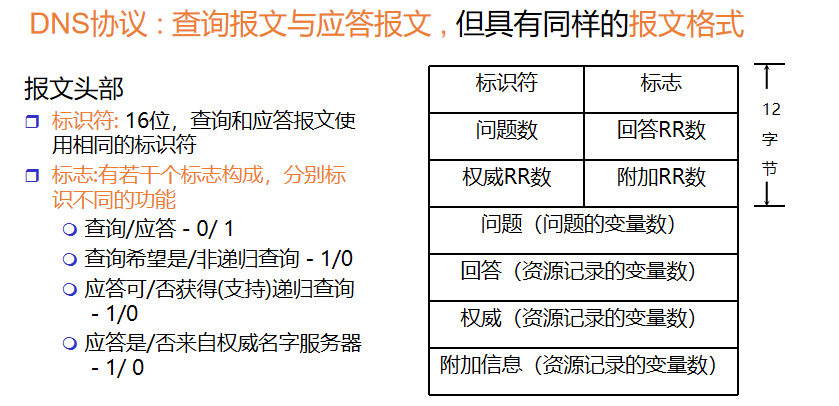
19、DNS协议、消息

20、DNS安全
DDoS攻击:对根域名服务器或顶级域名服务器发起拒绝服务攻击
重定向攻击:中间人攻击、DNS中毒攻击(发送欺骗的域名解析结果给DNS服务器)
利用DNS实现DDoS攻击: DNS反弹式拒绝服务攻击(DNS reflector attacks,又称DNS amplification attacks)。伪造客户地址向大量的dns服务器发出请求,导致客户无法访问dns服务器进行域名解析。
个人用户:本机Host文件被篡改/DNS劫持/DNS污染
21、CDN的作用和实现过程
挑战: 如何从海量的视频中,挑选出某些内容,采用流的方式发送给成千上万的用户?
选项1: 使用单点,庞大的服务器
单点故障
单点网络拥塞
远距离用户的访问路径很长
输出链路上发送同一视频的多份重复拷贝….
很显然: 这种方案不具有可扩展性
选项2: 将多份拷贝存储在地理上分散的不同站点来提供服务(CDN)
- 深入: 将CDN服务器部署在众多的接入网络中
- 靠近用户
- Akamai首创, 使用了1700多个位置
- 邀请做客: 在少量(例如10个)靠近接入网的关键位置(例如IXP),建造大集群,邀请到ISP做客
- Limelight等使用
CDN: 将内容的拷贝存储在CDN节点中
用户向CDN请求内容
- 被定向到附近的拷贝,取得内容
- 如果网络路径拥塞,则可能选择其他的拷贝

如果客户机请求一个html页面,在该页面包括了7个gif图片的引用,且所有对象都在一台服务器上。(1)当采用非持续连接时,客户机需要与web服务器建立( 8 )个TCP连接。(2)使用非流水线的持久HTTP连接使用的TCP连接数为( 1 ),总共需要( 9 )个RTT才能完成整个网页的获取。(3)在持久的带流水线HTTP连接中,客户端最少需要使用( 3 )个RTT才能完成整个网页的获取。
在浏览器和初始服务器之间使用非持续连接的话,一个TCP报文段是可能携带两个不同的HTTP服务请求报文的。(×)
两个不同的Web页面(例如,www.uestc.edu.cn/index.html 和mail.uestc.edu.cn/index.html)可以使用一个持久连接发送。( × )不属于同一个域名,位于同一个Web服务器上的多个页面可以通过同一条持续TCP连接发送给客户端。
在HTTP响应报文中的Date:首部指出了该响应中对象最后一次修改的时间。(x)响应报文中首部行的Date只记录服务器产生并且发送该响应报文的日期和时间。Last——modified才是记录了对象创建或者是最后一次修改的时间。
HTTP响应报文绝不会具有空的报文体。(x) head方法的响应报文是空报文体
以下所示HTTP报文头部的请求行或者状态行中,格式正确的是( C )
A、200 HTTP/1.1 OK
B、PUT HTTP/1.0 404 NOT FOUND
C、GET /star/abc.htm HTTP/1.1
D、200 GET HTTP/1.1 OK
假设用户A使用IE浏览器用基于Web的电子邮件账户向B发送邮件,B使用Foxmail作为用户代理来接收邮件,使用的协议可能是以下哪种情形? ( C )。
A、IMAP 、SMTP、POP3
B、HTTP、MIME、POP3
C、HTTP、SMTP、POP3
D、SMTP、SMTP、IMAP
假设用户A用浏览器登录电子邮箱给用户B发送邮件,同时,用户B也用浏览器登录电子邮箱接收邮件,邮件从用户A的主机到用户B的主机,使用了哪些应用层协议?如果用户A和B使用了Foxmail等邮件客户端呢?
用户A使用浏览器登录邮箱,使用了http协议访问发送方邮箱服务器,从发送方邮箱服务器到接收方邮箱服务器只能使用SMTP(Simple Mail Transfer Protocol)协议,用户B使用浏览器登录邮箱还是用的http协议。如果A使用了邮件客户端登录邮箱发送邮件,那么使用的是SMTP协议,用户B使用邮件客户端登录邮箱取邮件则使用的是POP3协议。
SMTP协议是面向ASCII编码的,那么它使用( D )支持非ASCII的数据传输。
A、MAIL B、POP3 C、IMAP D、MIME
SMTP协议和POP3协议分别是基于运输层的(D )。
A、UDP协议和UDP协议
B、UDP协议和TCP协议
C、TCP协议和UDP协议
D、TCP协议和TCP协议
电子邮件系统中,用户代理把邮件发往发送发邮件服务器、发送方邮件服务器把邮件发往接收方邮件服务器以及用户使用用户代理从接收方邮件服务器上读取邮件时,使用的协议可能是以下的哪种情形? (D )
A、IMAP 、SMTP、POP3
B、MIME、SMTP、POP3
C、SMTP、IMAP、POP3
D、SMTP、SMTP、IMAP
SMTP: 只能发送7比特 ASCII 码格式,而互联网邮件扩充 MIME 可以发送二进制文件。MIME 并没有改动或者取代 SMTP,而是增加邮件主体的结构,定义了非 ASCII 码的编码规则。 POP3的特点是只要用户从服务器上读取了邮件,就把该邮件删除。 IMAP 协议中客户端和服务器上的邮件保持同步,如果不手动删除邮件,那么服务器上的邮件也不会被删除。IMAP 这种做法可以让用户随时随地从任何一台机器去访问服务器上的邮件。
SMTP:发件人用户代理 —-发送邮件—> 发送方邮件服务器 、发送方邮件服务器 —-发送邮件—> 接收方邮件服务器
POP3/IMAP:接受方邮件服务器—-读取邮件—> 收件人用户代理
在使用浏览器打开某个网页时,用户输入网址后,浏览器首先要进行( B )。
A、和服务器建立TCP连接
B、域名到IP地址的解析
C、发送UDP分组到服务器
D、发出GET的HTTP命令来获得网页内容
Internet中域名解析依赖于由域名服务器组成的逻辑树。请问在域名解析过程中,主机上请求域名解析的软件不需要知道以下哪些信息? ( C )。
①本地域名服务器的端口号 ②本地域名服务器父结点的IP ③域名服务器树根结点的IP
A、①② B、①②③ C、②③ D、①②③
主机上请求域名解析的软件只需要知道本地域名服务器的IP地址和端口号,然后向本地域名服务器发送DNS查询请求。本地域名服务器会根据自己的缓存和配置,返回查询结果或者将查询请求转发给其他域名服务器(包括根域名服务器、顶级域名服务器)。
关于DNS描述错误的是( D )。
A、将主机名转换为IP地址
B、所有的DNS请求和回答报文使用的是53端口发送
C、在因特网上DNS功能的实现采用的是分布式、层次数据库
D、DNS的请求和回答报文采用的是TCP协议进行传输的
DNS使用UDP协议进行传输,所有的DNS请求和回答报文都使用53端口发送。
查询链中的DNS服务器如果不是某主机名的权威服务器,对于该主机名,它必将包含对应的两种类型记录,分别为( C )。
A、CNAME和A B、MX和NS C、NS和A D、NS和MX
当查询链中的DNS服务器不是某主机名的权威服务器时,它可能包含NS记录和A记录。NS记录(Name Server Record)是一种DNS记录类型,用于指定某个域名的权威服务器。例如,如果查询链中的DNS服务器不是www.example.com 的权威服务器,那么它可能包含一条NS记录,指定www.example.com 的权威服务器为dns1.example.com。A记录(Address Record)是一种DNS记录类型,用于将域名映射到IPv4地址。例如,如果查询链中的DNS服务器不是www.example.com 的权威服务器,那么它可能包含一条A记录,将www.example.com 映射到对应的IP地址。
HTTP 协议中,接收方如何区分首部行和数据部分(C )
A.报文中首部行长度字段
B. 报文中使用 DATA 指令指示首部行结束
C. 报文中首部行结束时添加空行
D. 报文中首部行结束时增加“.”作为分隔行
DNS 实现的功能不包括(D )
A.主机名和 IP 地址映射 B. 别名处理 C. 负载分配 D. 路由选择
DNS并不负责路由选择,这一功能由路由器等网络设备实现。
假定你在浏览器中点击一条超链接获得Web页面。相关联的URL的IP地址没有缓存在本地主机上,因此必须使用DNS lookup以获得该IP地址。如果主机从DNS得到IP地址之前已经访问了n个DNS服务器;相继产生的RTT依次为RTT1、…、RTTn。进一步假定与链路相关的Web页面只包含一个对象,即由少量的HTML文本组成。令RTT0表示本地主机和包含对象的服务器之间的RTT值。假定该对象传输时间为零,则从该客户点击该超链接到它接收到该对象需要多长时间?
RTT1+…+RTTn+ 2RTT0(解析ip地址的时间+建立tcp连接和请求得到web页面的时间)
参照上题,假定在同一服务器上某HTML文件引用了 8个非常小的对象。忽略发送时间,在下列情况下需要多长时间:
(1)没有并行TCP连接的非持续HTTP。
RTT1+…+RTTn+ 18RTT0
(2)配置有5个并行连接的非持续HTTP。
RTT1+…+RTTn+ 6RTT0
(3)持续HTTP.
流水 :RTT1+…+RTTn+ 3RTT0
非流水: RTT1+…+RTTn+ 10RTT0
考虑下图,其中有一个机构的网络和因特网相连。假定对象的平均长度为850 000bits,从这个机构网的浏览器到初始服务器的平均请求率是每秒16个请求。还假定从接入链路的因特网一侧的路由器转发一个HTTP请求开始,到接收到其响应的平均时间是3秒。将总的平均响应时间建模为平均接入时延(即从因特网路由器到机构路由器的时延)和平均因特网时延之和。对于平均接入时延,使用△/(1-△B),式中△是跨越接入链路发送一个对象的平均时间,B是对象对该接入链路的平均到达率。
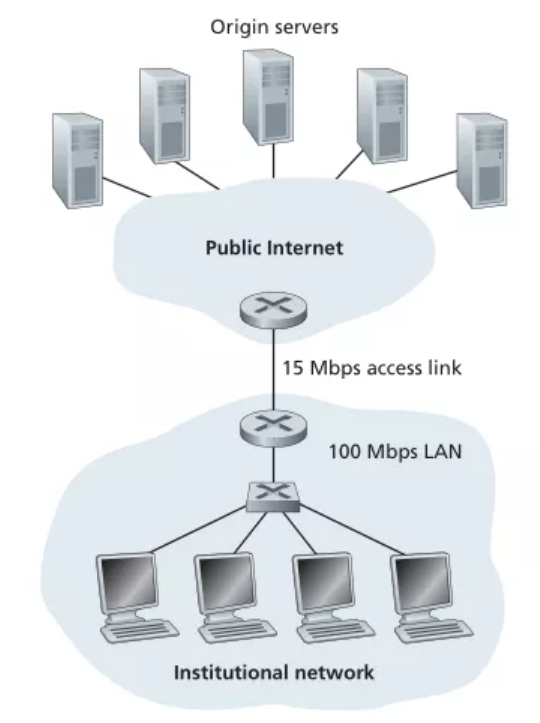
(1)求出总的平均响应时间。
(2)现在假定在这个机构LAN中安装了一个缓存器。假定未命中率为0.4,求出总的响应时间。
(1)由题意:总平均响应时间=平均接入时延+平均因特网时延。
其中,平均因特网时延=3秒
平均接入时延=△/(1-△B)
△=850000bit/15Mbps=850000bit / 15000000bit/s=0.0567s
B=16请求/s
△B=16*0.0567≈0.907
平均接入时延=0.0567/(1-0.907)≈0.6s
总平均响应时延=0.6+3=3.6s
(2)未命中率0.4,所以有60%可以通过缓存器立即响应。
平均接入时延=△/(1-△B)=0.0567/(1-0.4*0.907)≈0.089s
所以总响应时间=0.6 * 0 +(0.089+3) * 0.4 ≈ 1.24s
考虑一条10米短链路,某发送方经过它能够以150bps速率双向传输。假定包含数据分组是 100Kbits,仅包含控制(如ACK或握手)的分组是200bits。假定N个并行连接每个都获 得1/N的链路带宽。现在考虑HTTP协议,并且假定每个下载对象是100Kbits,这些初始下载对象包含10个来自相同发送方的引用对象。在这种情况下,经非持续HTTP的并行实例的并行下载有意义吗?现在考虑持续HTTP。你期待这比非持续的情况有很大增益吗?评价并解释你的答案。

每个下载的对象可以完全放入一个数据包中。令Tp表示客户端和服务器之间的单向传播延迟。传输第一个文件之后再并行传输,由于非持续HTTP需要重新建立TCP连接(三次握手),并行下载将允许10个连接共享150位/秒的带宽,每个连接只有15个位/秒,因此,接收所有对象所需的总时间为:

现在考虑一个持久的HTTP连接,所需的总时间为:

增益似乎不是很大。
考虑在上一个习题中引出的情况。现在假定该链路由Bob和4个其他用户所共享。Bob使用非持续HTTP的并行实例,而其他4个用户使用无并行下载的非持续HTTP。
a. Bob的并行连接能够帮助他更快地得到Web页面吗?
b. 如果所有5个用户打开5个非持续HTTP并行实例,那么Bob的并行连接仍将是有好处的吗?为什么?
a)是的,因为Bob有更多的连接,他可以获得更大的带宽份额。
b)是的,Bob 仍然需要执行并行下载;否则他将比其他四个用户获得更少的带宽。
 微信
微信 支付宝
支付宝





