# 元素入堆 heapq.heappush(max_heap, flag * 1) heapq.heappush(max_heap, flag * 3) heapq.heappush(max_heap, flag * 2) heapq.heappush(max_heap, flag * 5) heapq.heappush(max_heap, flag * 4)
# 获取堆顶元素 peek: int = flag * max_heap[0] # 5
# 堆顶元素出堆 # 出堆元素会形成一个从大到小的序列 val = flag * heapq.heappop(max_heap) # 5 val = flag * heapq.heappop(max_heap) # 4 val = flag * heapq.heappop(max_heap) # 3 val = flag * heapq.heappop(max_heap) # 2 val = flag * heapq.heappop(max_heap) # 1
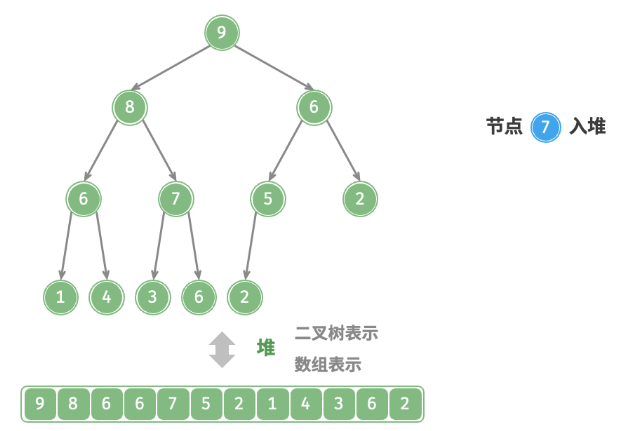
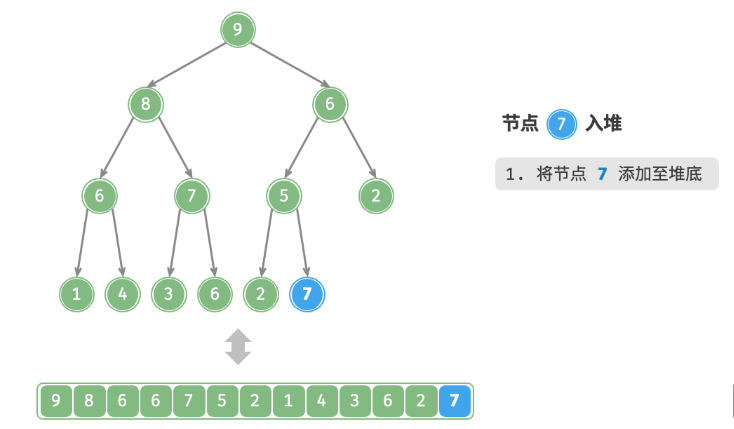
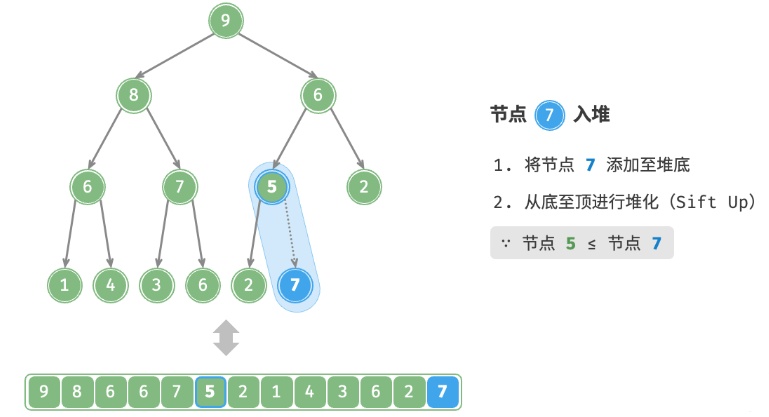
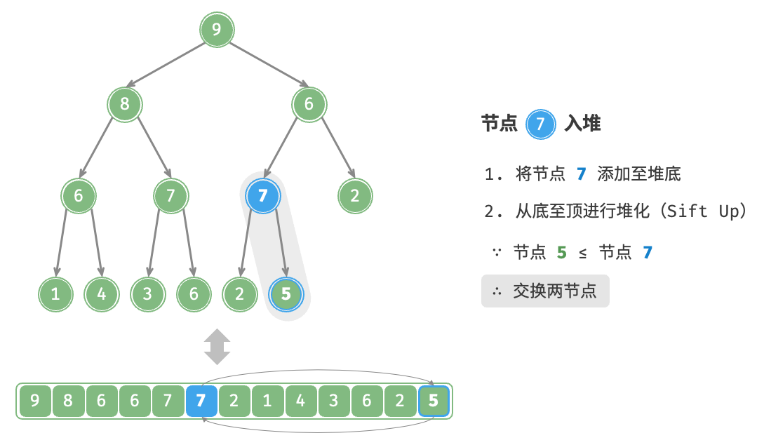
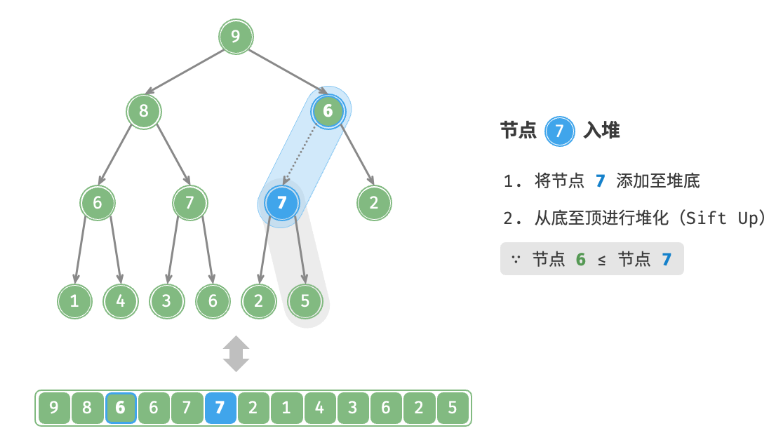
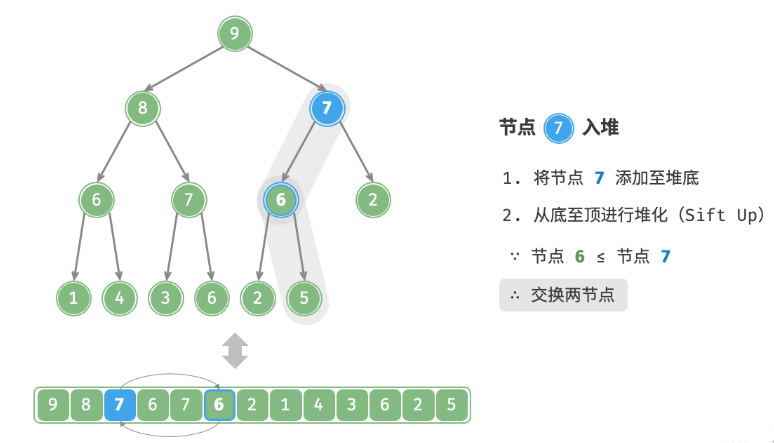
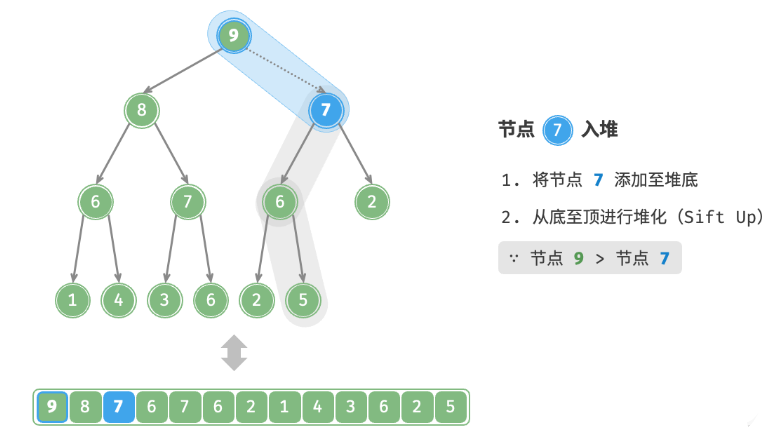
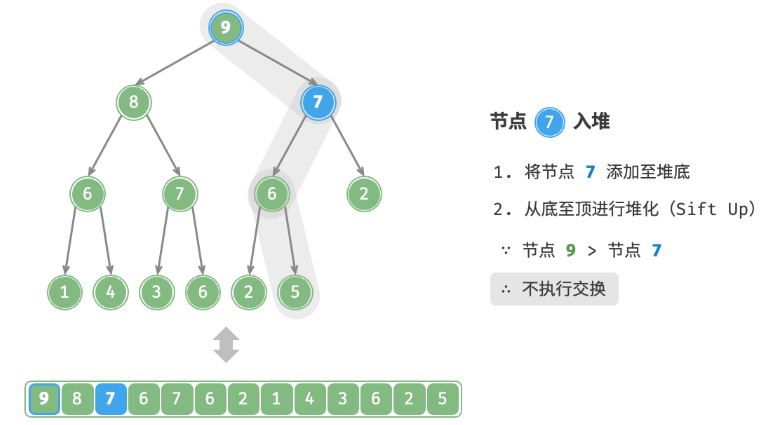
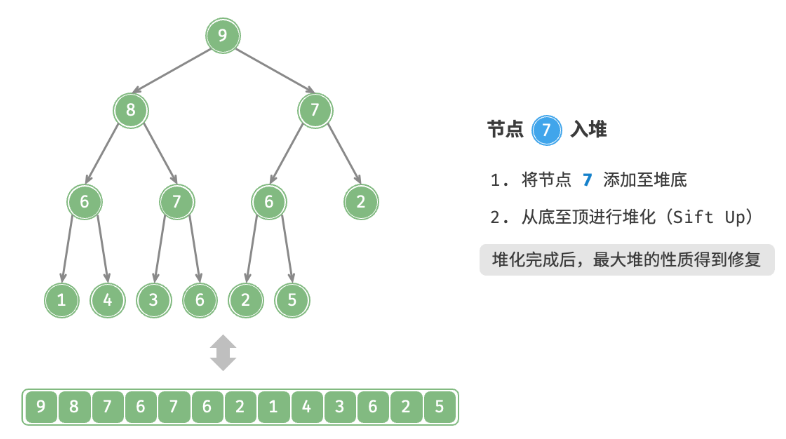
给定元素 val ,首先将其添加到堆底。添加之后,由于 val 可*其他元素,堆的成立条件可能已被破坏。因此,需要修复从插入节点到根节点的路径上的各个节点,这个操作被称为堆化。考虑从入堆节点开始,从底至顶执行堆化。如下图所示,我们比较插入节点与其父节点的值,如果插入节点更大,则将它们交换。然后继续执行此操作,从底至顶修复堆中的各个节点,直至越过根节点或遇到无须交换的节点时结束。
defsift_up(self, i: int): """从节点 i 开始,从底至顶堆化""" whileTrue: # 获取节点 i 的父节点 p = self.parent(i) # 当“越过根节点”或“节点无须修复”时,结束堆化 if p < 0or self.max_heap[i] <= self.max_heap[p]: break # 交换两节点 self.swap(i, p) # 循环向上堆化 i = p
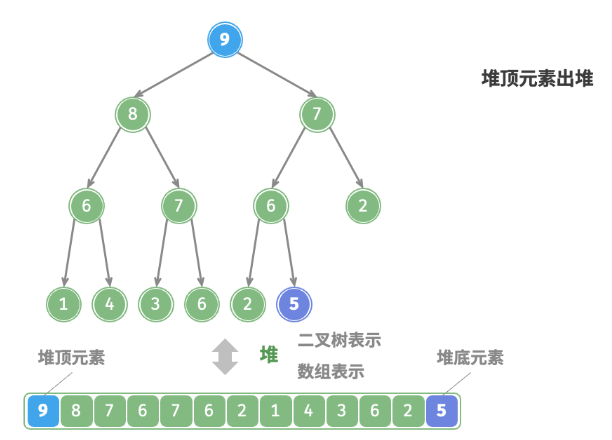
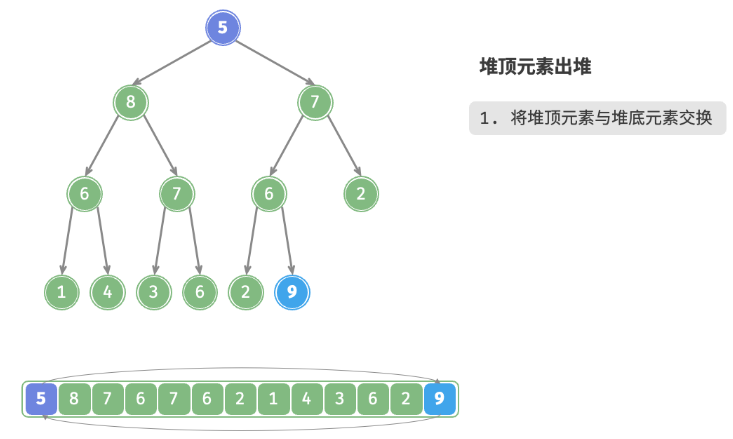
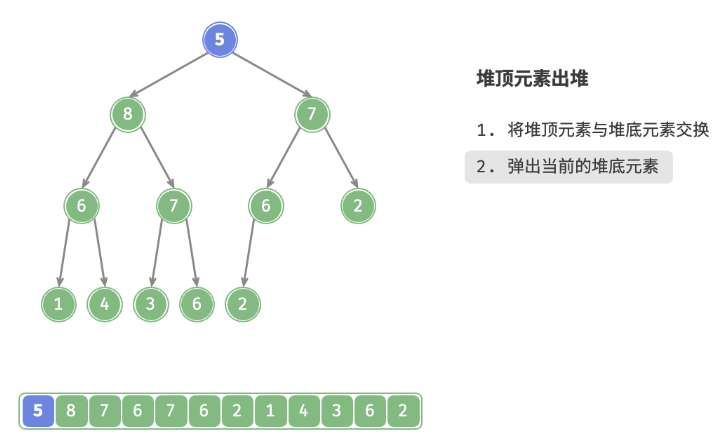
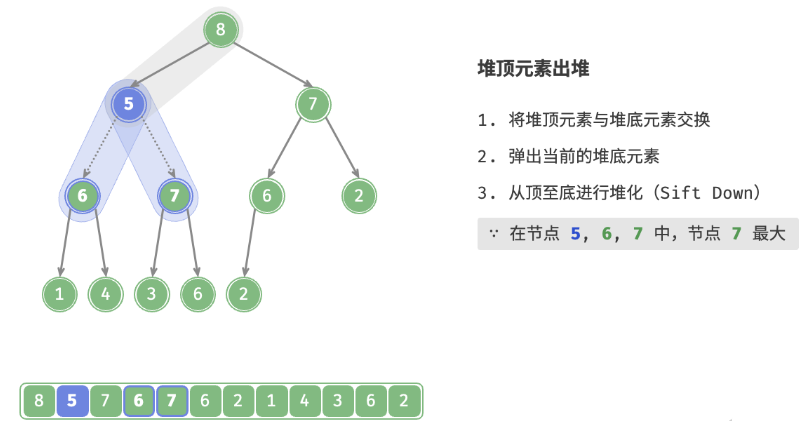
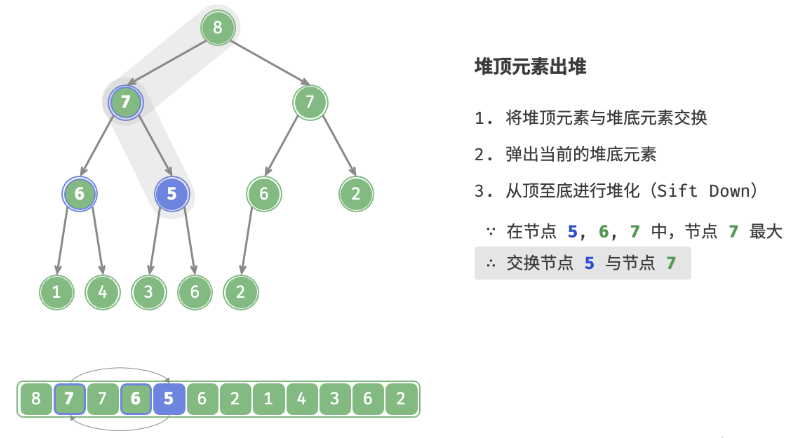
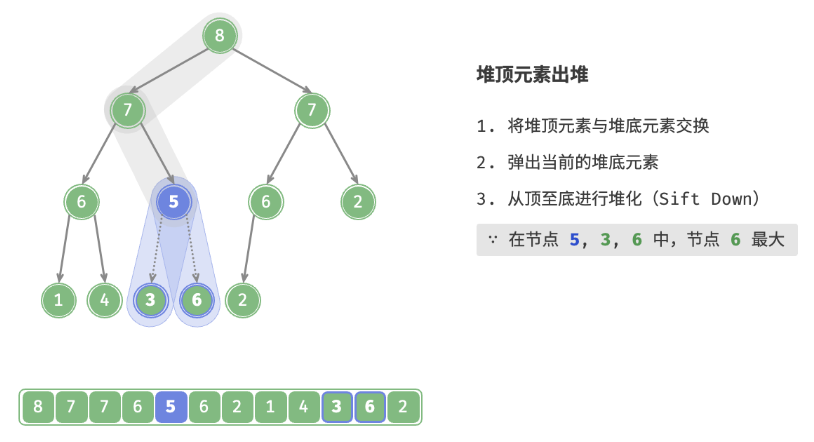
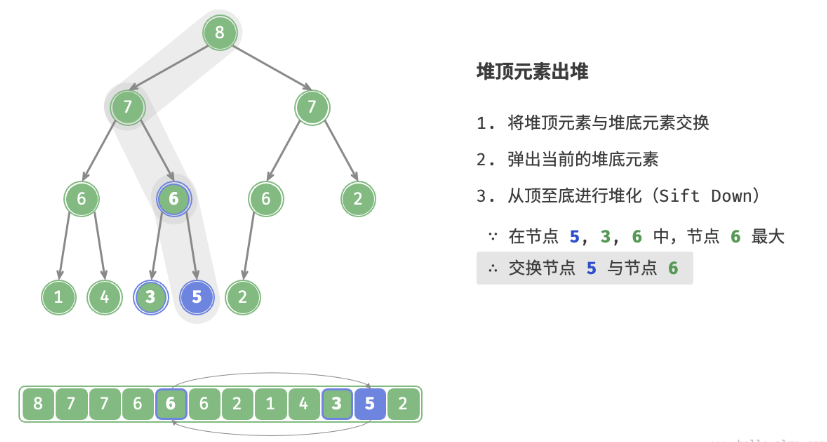
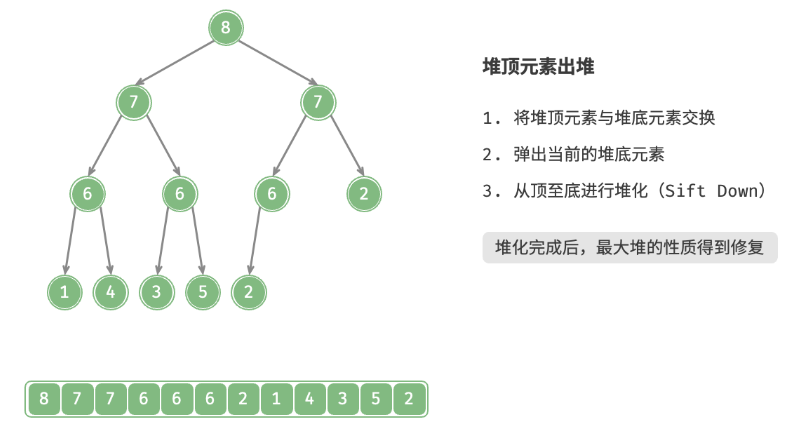
defpop(self) -> int: """元素出堆""" # 判空处理 if self.is_empty(): raise IndexError("堆为空") # 交换根节点与最右叶节点(即交换首元素与尾元素) self.swap(0, self.size() - 1) # 删除节点 val = self.max_heap.pop() # 从顶至底堆化 self.sift_down(0) # 返回堆顶元素 return val
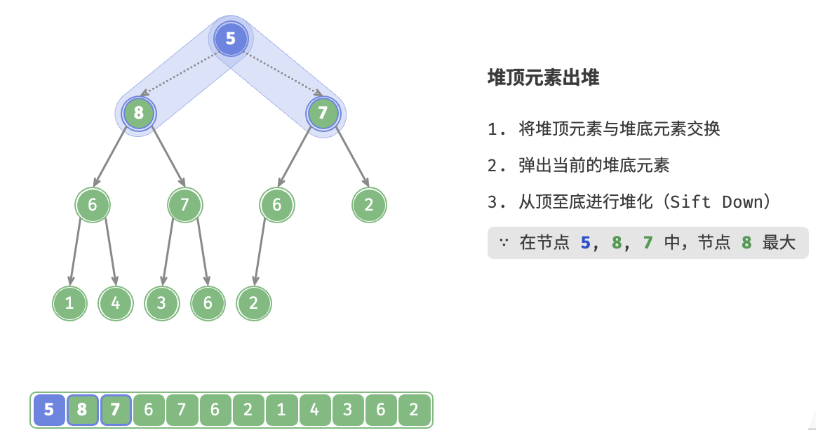
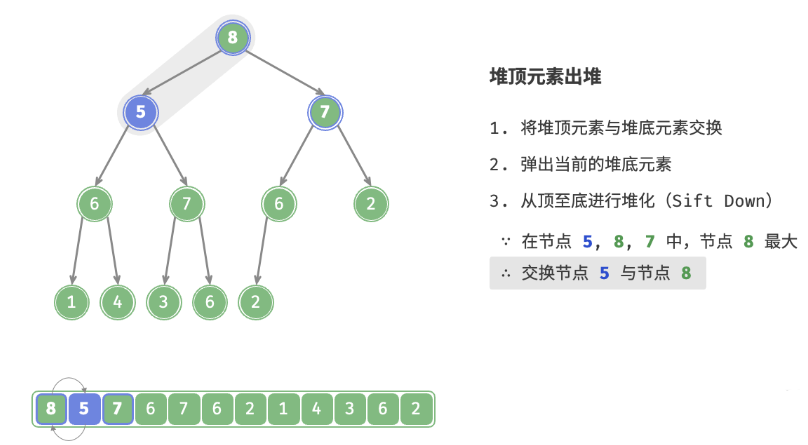
defsift_down(self, i: int): """从节点 i 开始,从顶至底堆化""" whileTrue: # 判断节点 i, l, r 中值最大的节点,记为 ma l, r, ma = self.left(i), self.right(i), i if l < self.size() and self.max_heap[l] > self.max_heap[ma]: ma = l if r < self.size() and self.max_heap[r] > self.max_heap[ma]: ma = r # 若节点 i 最大或索引 l, r 越界,则无须继续堆化,跳出 if ma == i: break # 交换两节点 self.swap(i, ma) # 循环向下堆化 i = ma
/* 从节点 i 开始,从顶至底堆化 */ func(h *maxHeap) siftDown(i int) { fortrue { // 判断节点 i, l, r 中值最大的节点,记为 max l, r, max := h.left(i), h.right(i), i if l < h.size() && h.data[l].(int) > h.data[max].(int) { max = l } if r < h.size() && h.data[r].(int) > h.data[max].(int) { max = r } // 若节点 i 最大或索引 l, r 越界,则无须继续堆化,跳出 if max == i { break } // 交换两节点 h.swap(i, max) // 循环向下堆化 i = max } }
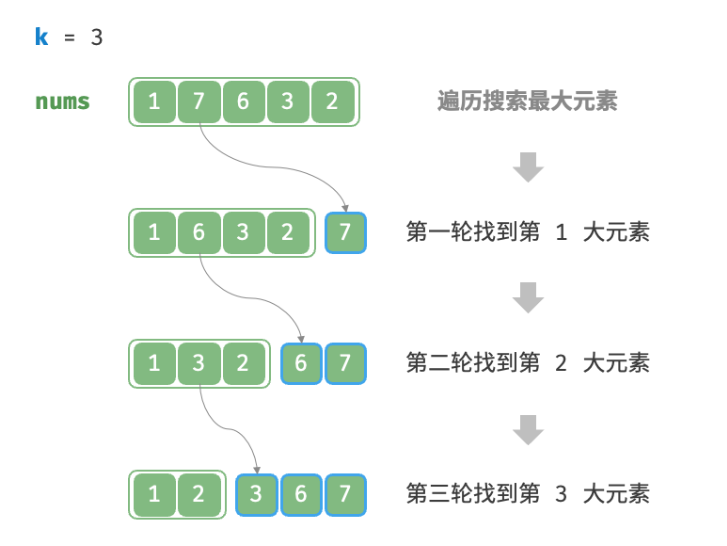
deffindKthLargest(nums, k): result = [] for i inrange(k): max_num = max(nums) result.append(max_num) nums.remove(max_num) return result
Go:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
funcfindKthLargest(nums []int, k int) []int { result := make([]int, k) for i := 0; i < k; i++ { max := nums[0] index := 0 for i, num := range nums { if num > max { max = num index = i } } result[i] = max nums = append(nums[:index], nums[index+1:]...) } return result }
总共执行了n轮入堆和出堆,堆的最大长度为k,因此时间复杂度为 O(nlogk) 。该方法的效率很高,当 k 较小时,时间复杂度趋向 O(n) ;当 k 较大时,时间复杂度不会超过 O(nlogn) 。另外,该方法适用于动态数据流的使用场景。在不断加入数据时,可以持续维护堆内的元素,从而实现最大k个元素的动态更新。
Python:
1 2 3 4 5 6 7 8 9 10 11 12 13
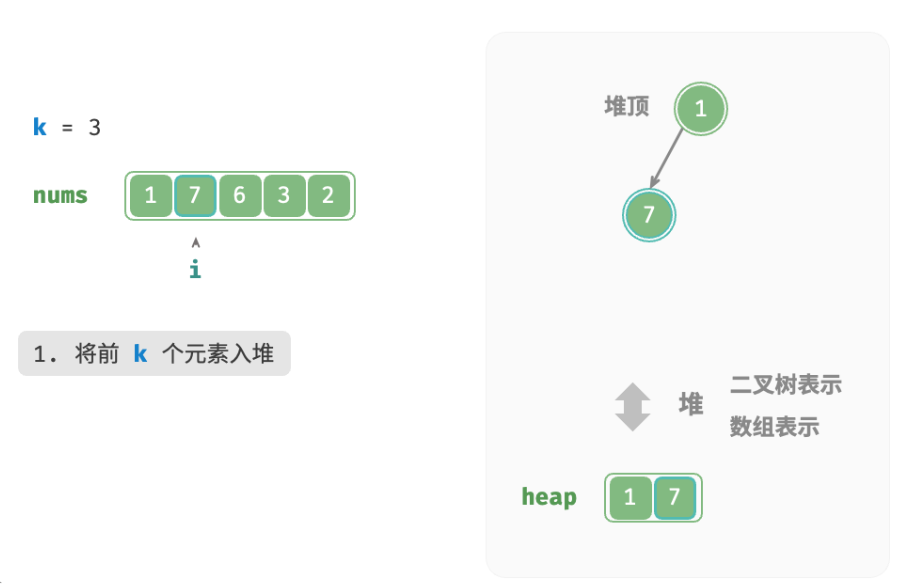
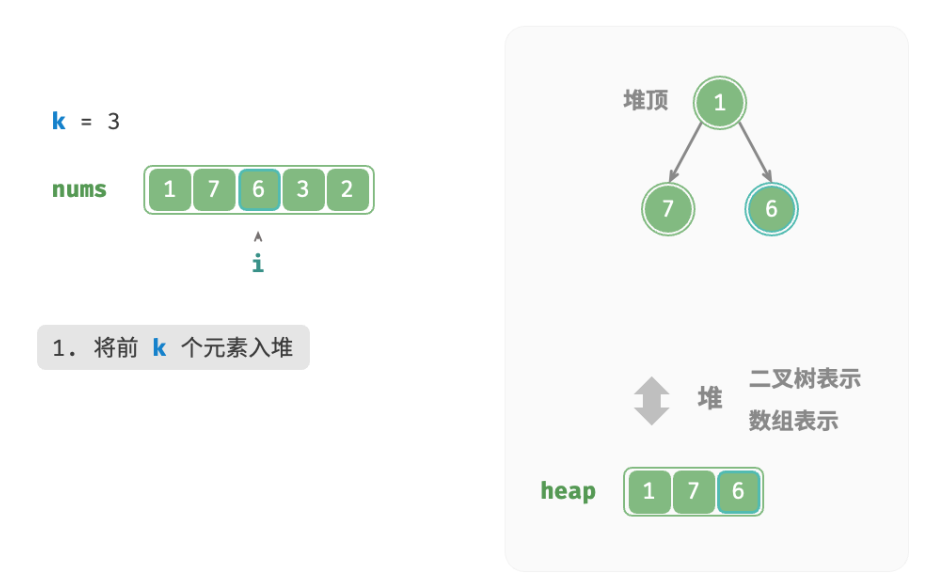
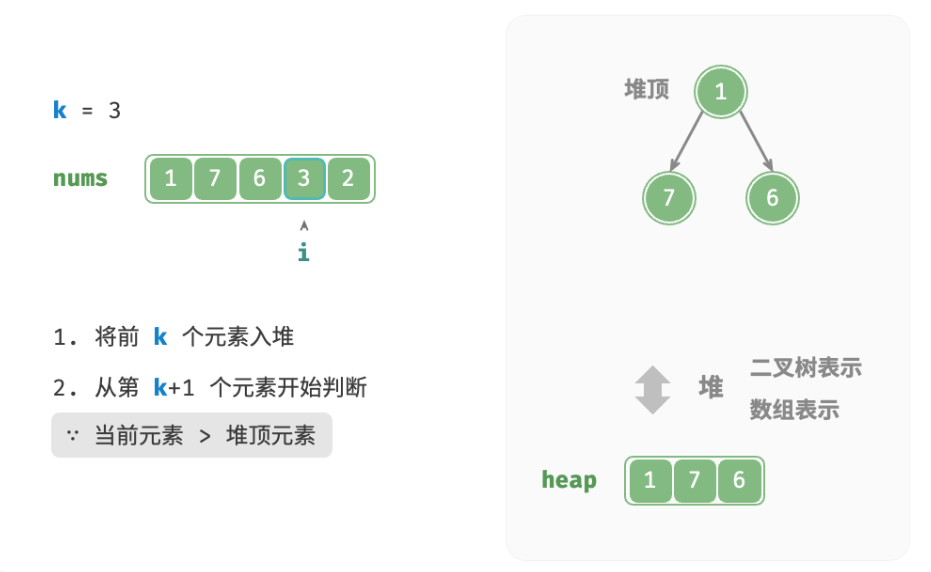
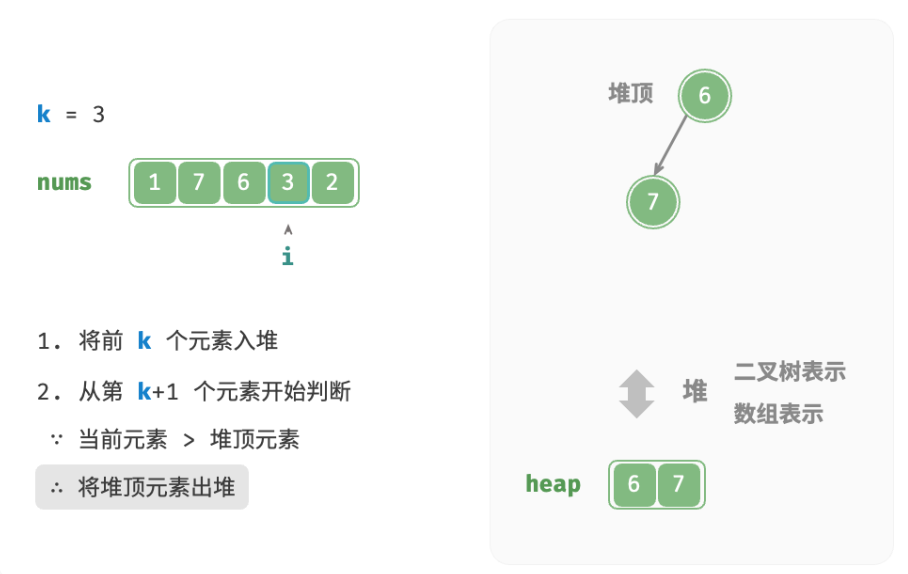
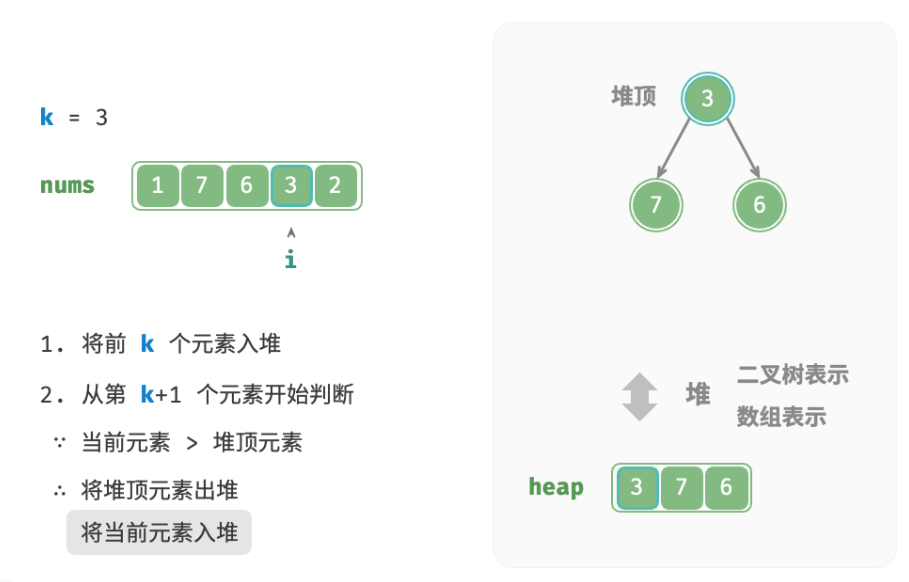
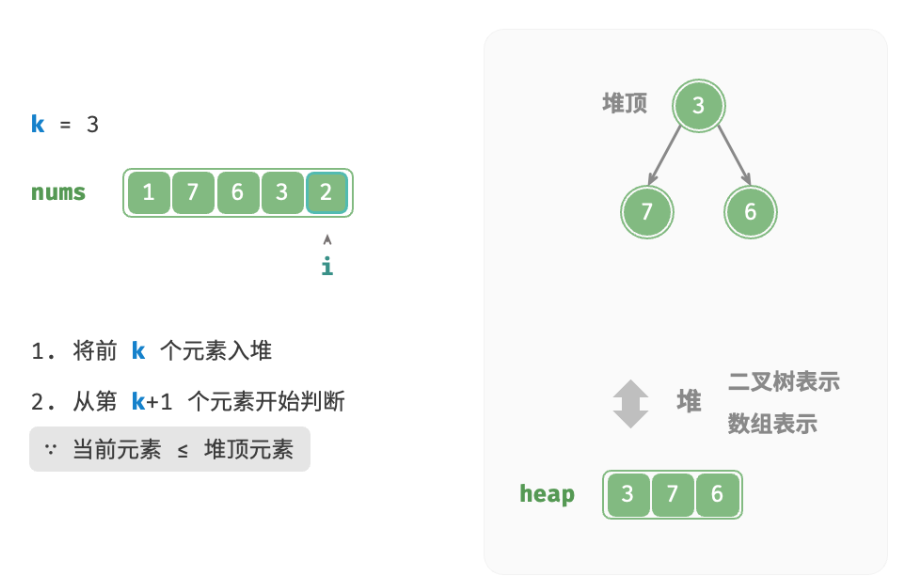
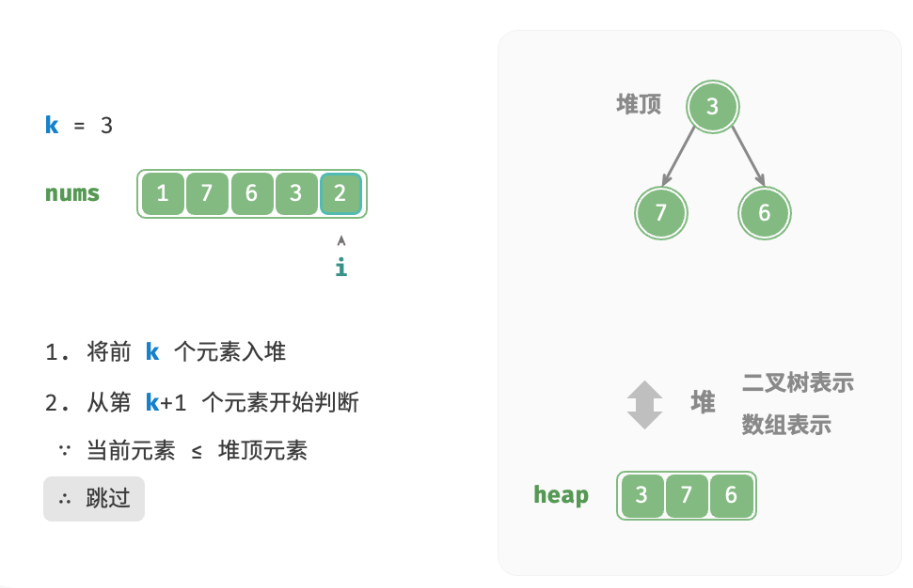
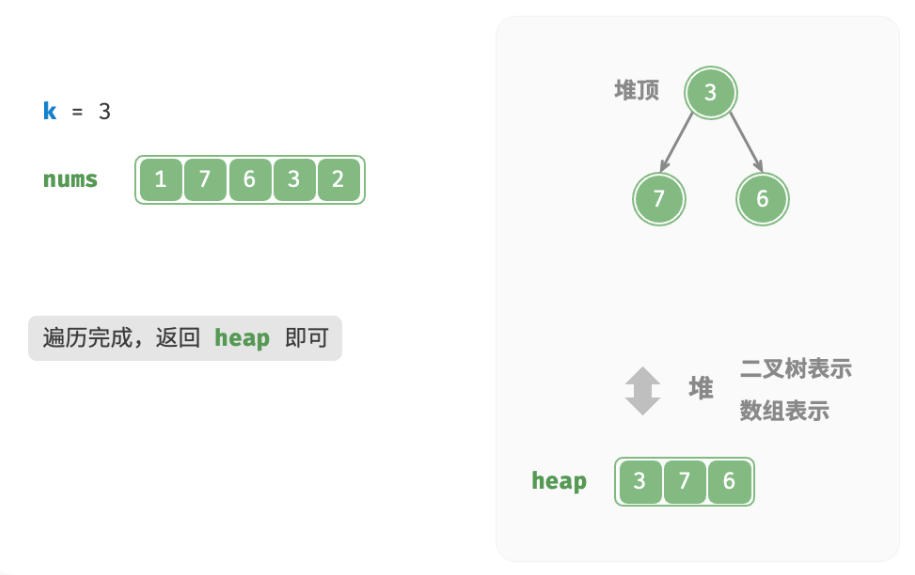
deftop_k_heap(nums: list[int], k: int) -> list[int]: """基于堆查找数组中最大的 k 个元素""" heap = [] # 将数组的前 k 个元素入堆 for i inrange(k): heapq.heappush(heap, nums[i]) # 从第 k+1 个元素开始,保持堆的长度为 k for i inrange(k, len(nums)): # 若当前元素大于堆顶元素,则将堆顶元素出堆、当前元素入堆 if nums[i] > heap[0]: heapq.heappop(heap) heapq.heappush(heap, nums[i]) return heap
Go:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
/* 基于堆查找数组中最大的 k 个元素 */ functopKHeap(nums []int, k int) *minHeap { h := &minHeap{} heap.Init(h) // 将数组的前 k 个元素入堆 for i := 0; i < k; i++ { heap.Push(h, nums[i]) } // 从第 k+1 个元素开始,保持堆的长度为 k for i := k; i < len(nums); i++ { // 若当前元素大于堆顶元素,则将堆顶元素出堆、当前元素入堆 if nums[i] > h.Top().(int) { heap.Pop(h) heap.Push(h, nums[i]) } } return h }

 微信
微信 支付宝
支付宝



