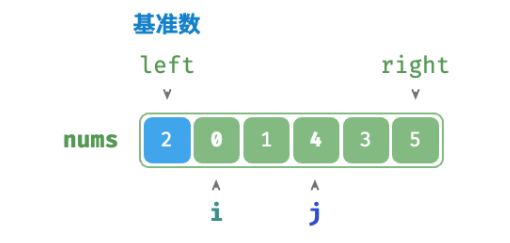
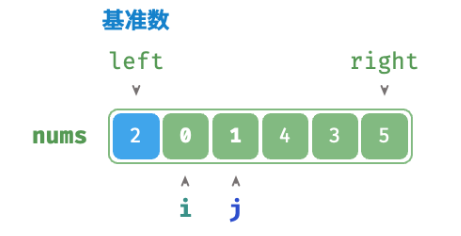
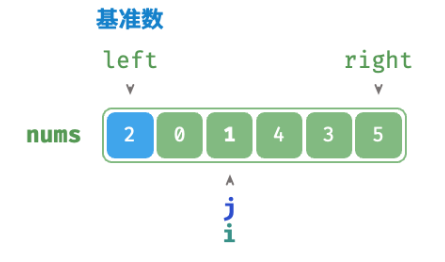
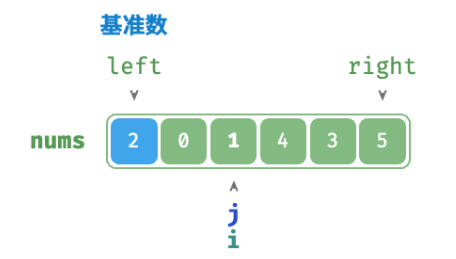
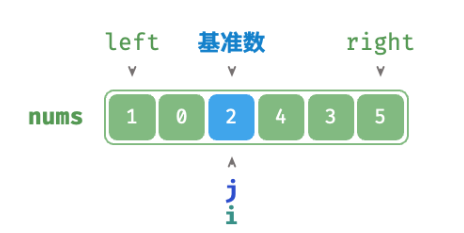
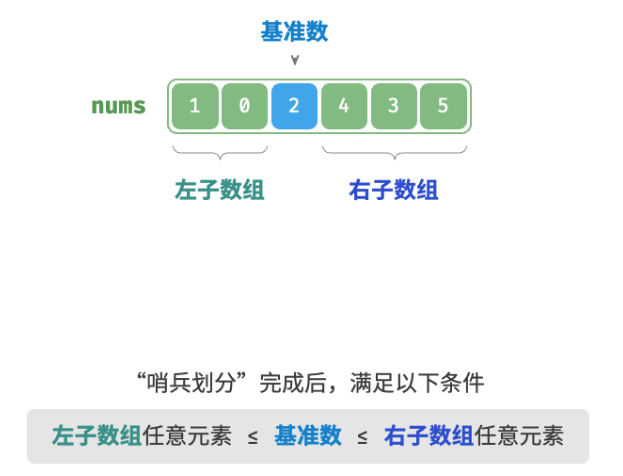
/* 哨兵划分 */ func(q *quickSort) partition(nums []int, left, right int) int { // 以 nums[left] 作为基准数 i, j := left, right for i < j { for i < j && nums[j] >= nums[left] { j-- // 从右向左找首个小于基准数的元素 } for i < j && nums[i] <= nums[left] { i++ // 从左向右找首个大于基准数的元素 } // 元素交换 nums[i], nums[j] = nums[j], nums[i] } // 将基准数交换至两子数组的分界线 nums[i], nums[left] = nums[left], nums[i] return i // 返回基准数的索引 }
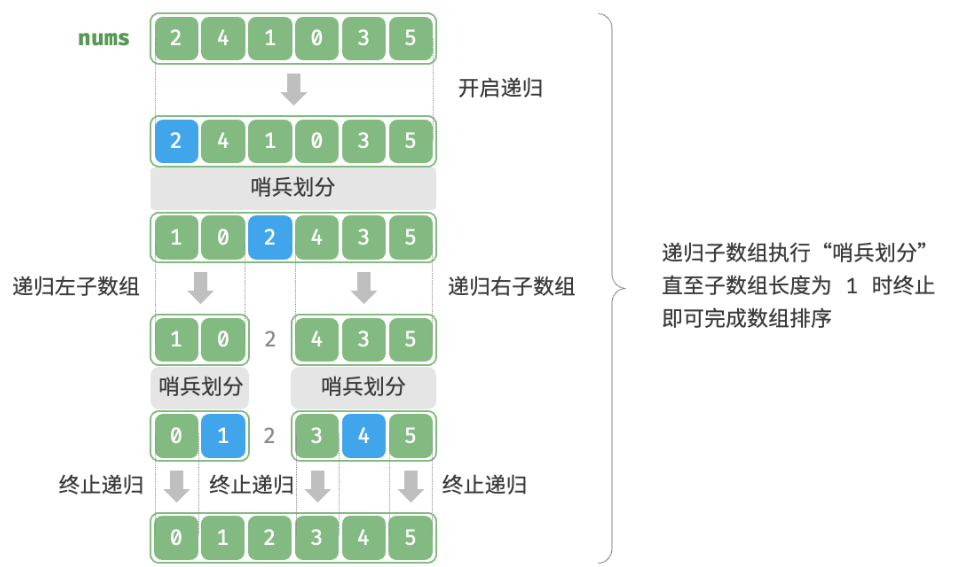
/* 快速排序 */ func(q *quickSort) quickSort(nums []int, left, right int) { // 子数组长度为 1 时终止递归 if left >= right { return } // 哨兵划分 pivot := q.partition(nums, left, right) // 递归左子数组、右子数组 q.quickSort(nums, left, pivot-1) q.quickSort(nums, pivot+1, right) }
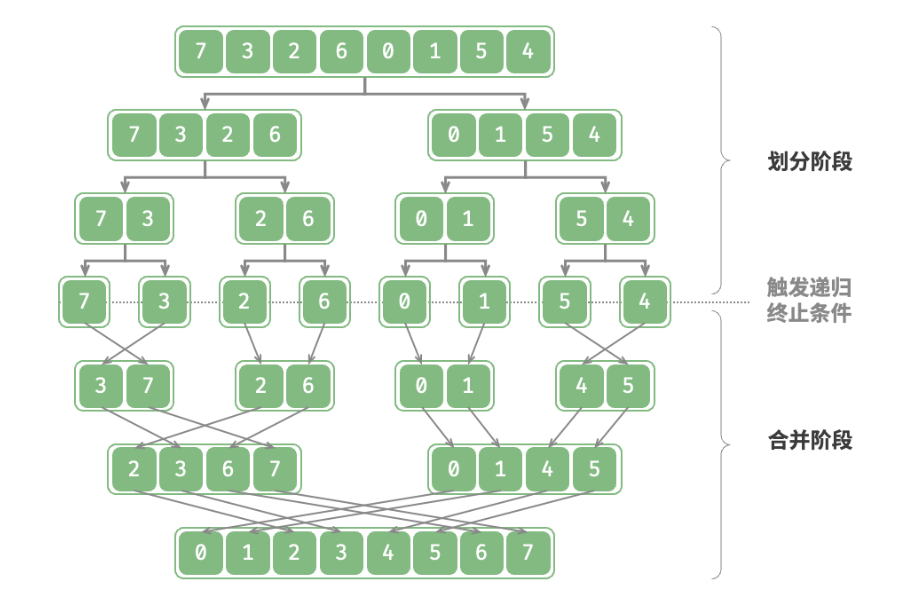
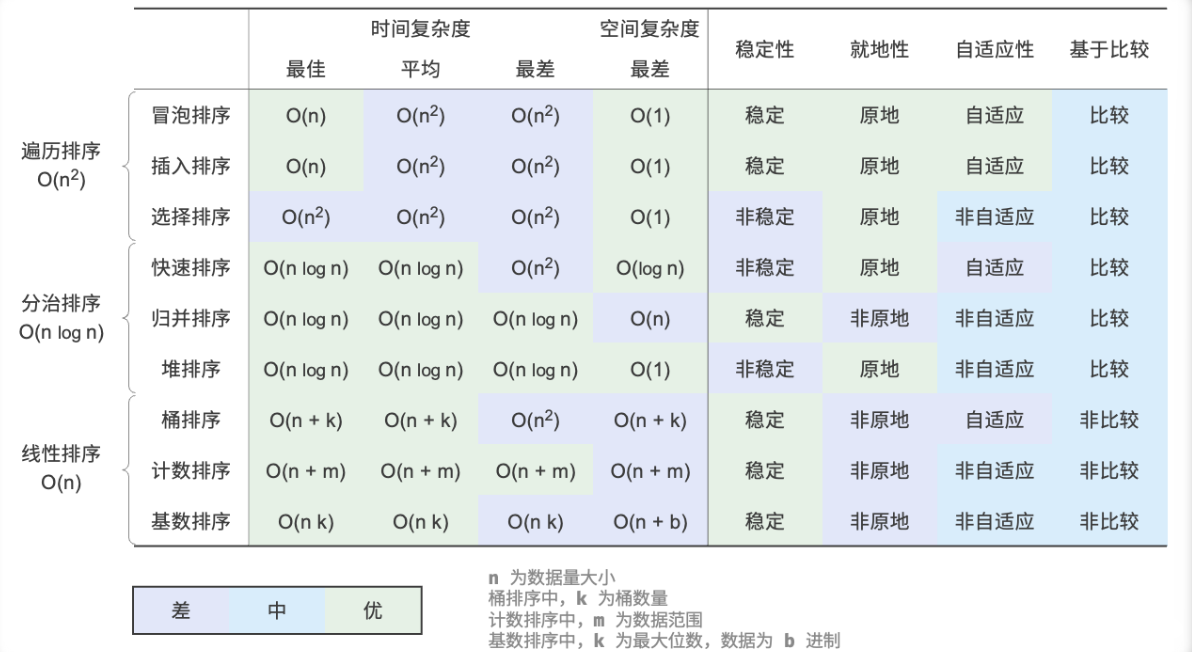
时间复杂度 O(nlogn)、自适应排序:在平均情况下,哨兵划分的递归层数为 logn ,每层中的总循环数为 n ,总体使用 O(nlogn) 时间。在最差情况下,每轮哨兵划分操作都将长度为 n 的数组划分为长度为 0 和 n−1 的两个子数组,此时递归层数达到 n 层,每层中的循环数为 n ,总体使用 O(n^2) 时间。
空间复杂度 O(n)、原地排序:在输入数组完全倒序的情况下,达到最差递归深度 n ,使用 O(n) 栈帧空间。排序操作是在原数组上进行的,未借助额外数组。
defsift_down(nums: list[int], n: int, i: int): """堆的长度为 n ,从节点 i 开始,从顶至底堆化""" whileTrue: # 判断节点 i, l, r 中值最大的节点,记为 ma l = 2 * i + 1 r = 2 * i + 2 ma = i if l < n and nums[l] > nums[ma]: ma = l if r < n and nums[r] > nums[ma]: ma = r # 若节点 i 最大或索引 l, r 越界,则无须继续堆化,跳出 if ma == i: break # 交换两节点 nums[i], nums[ma] = nums[ma], nums[i] # 循环向下堆化 i = ma
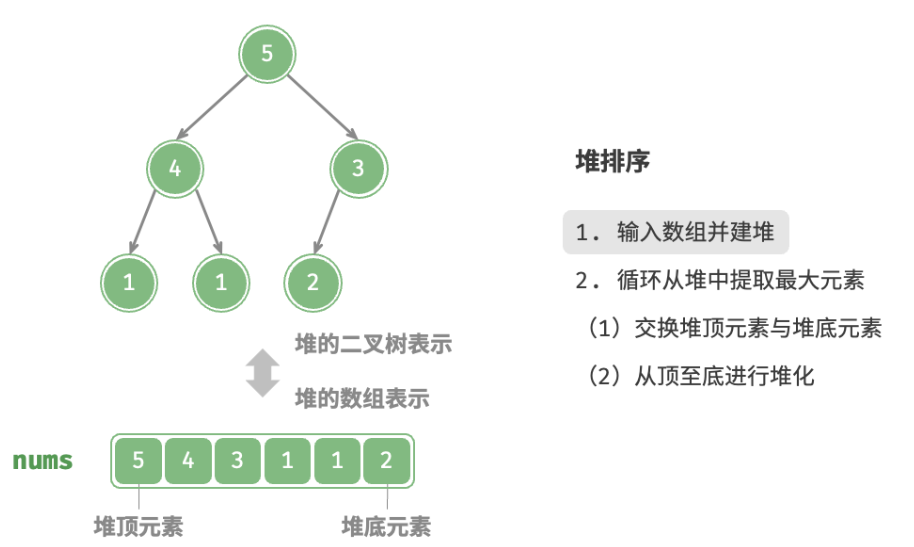
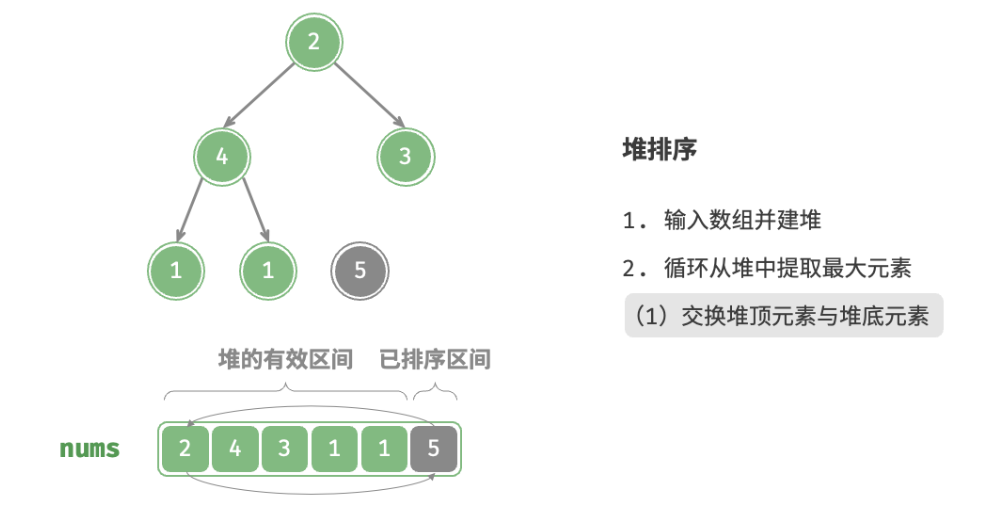
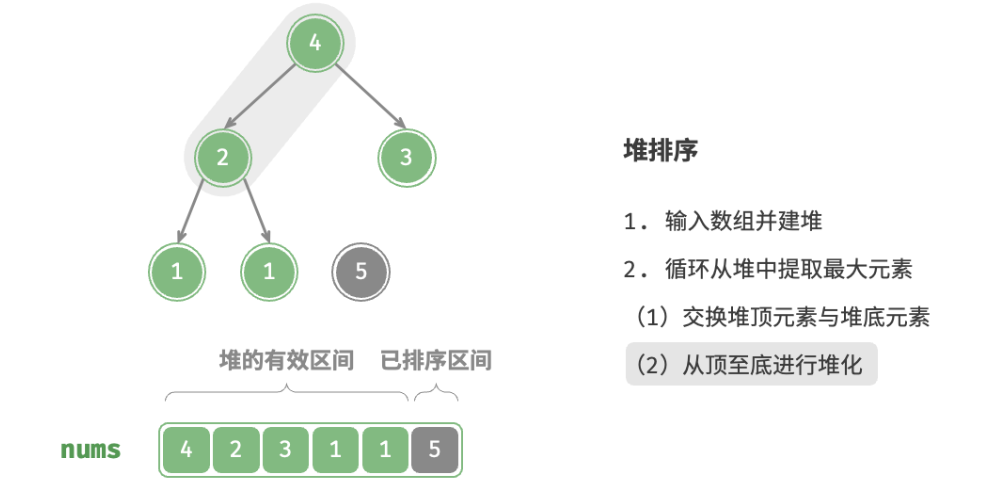
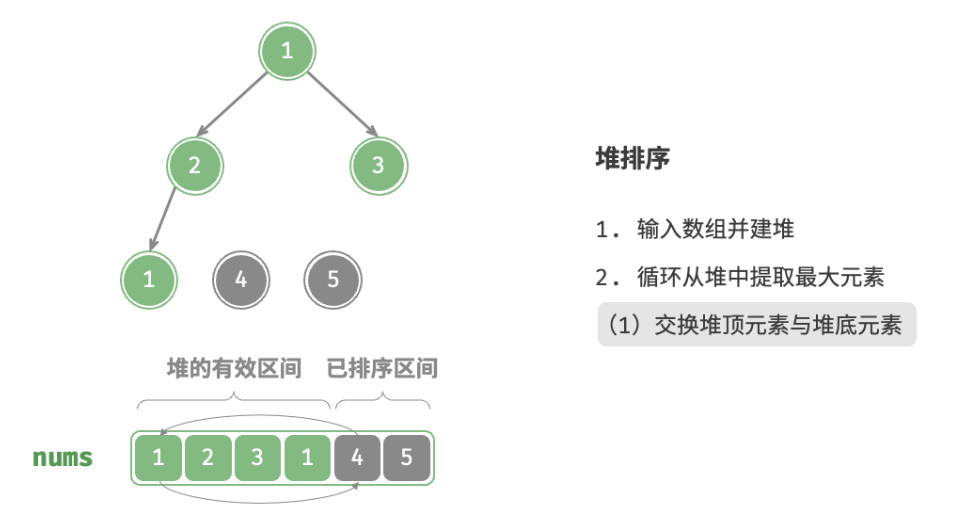
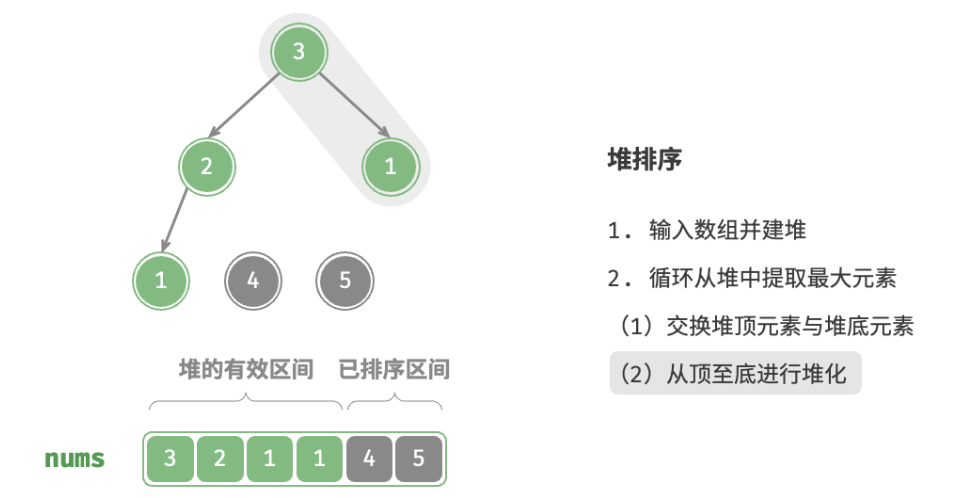
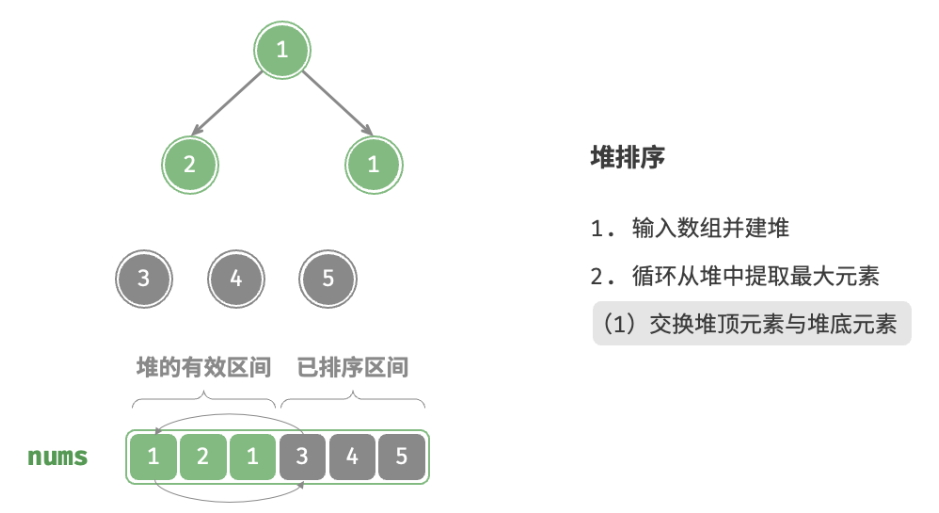
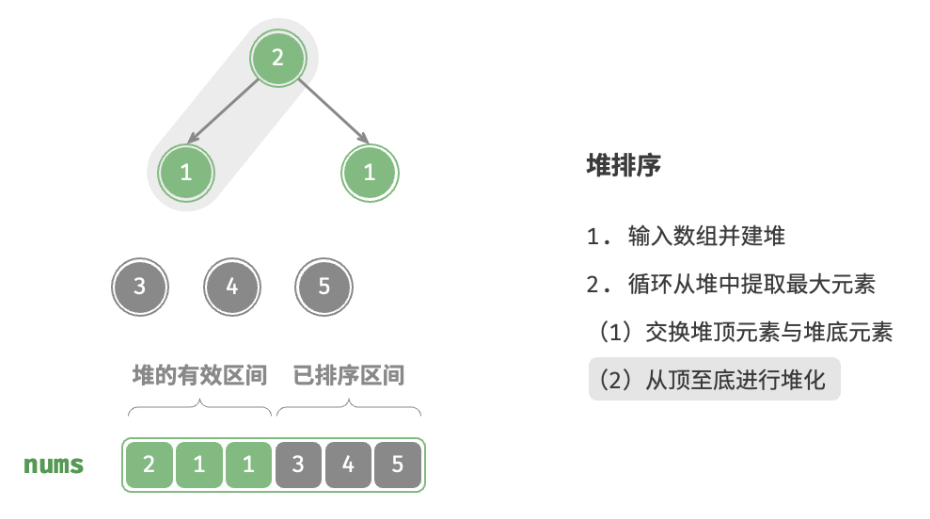
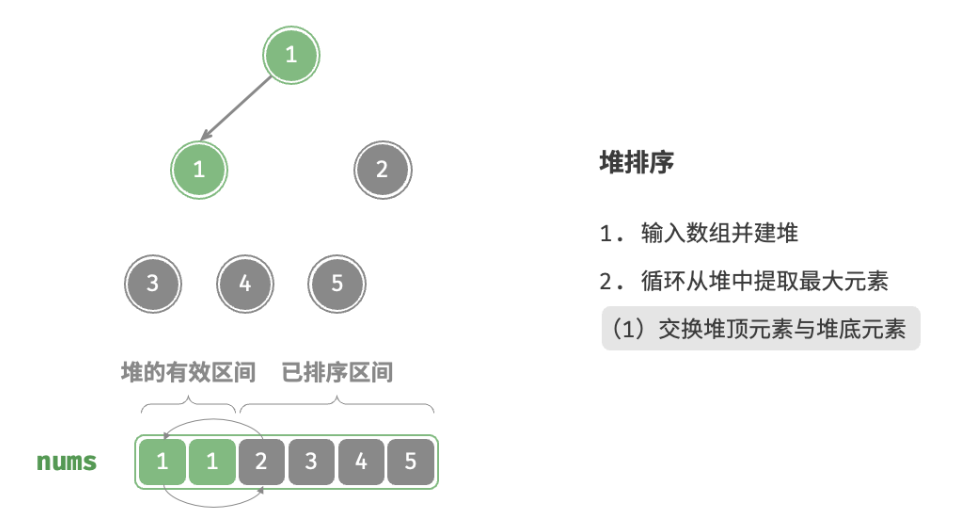
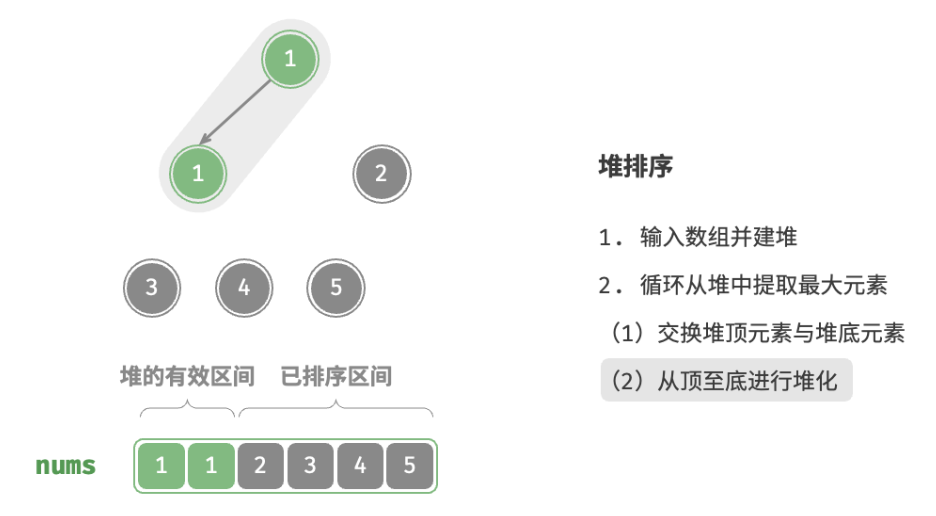
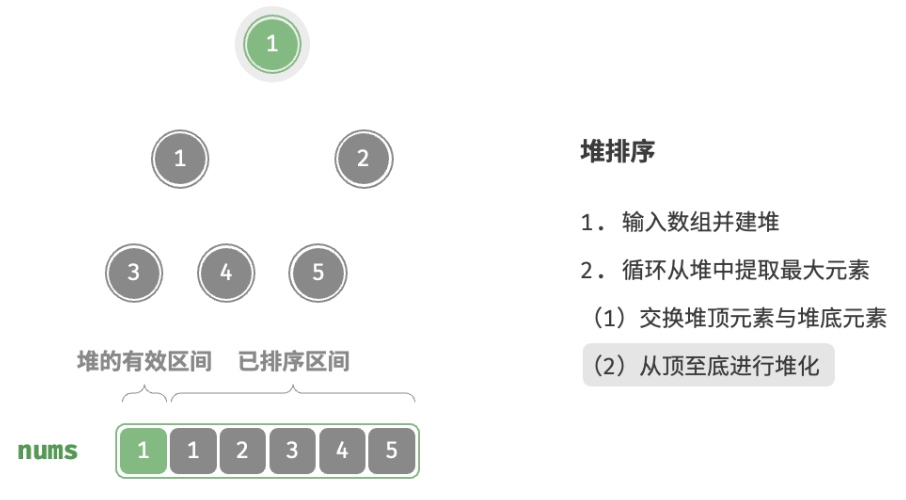
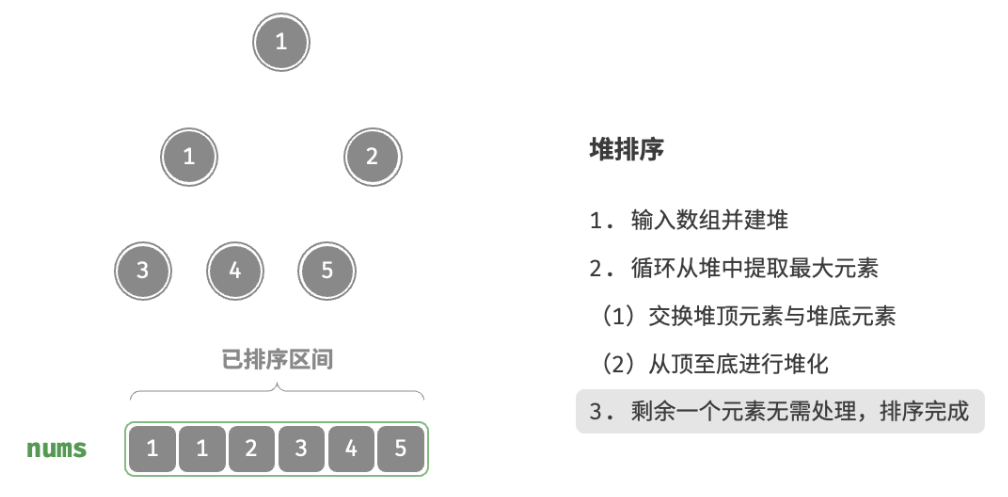
defheap_sort(nums: list[int]): """堆排序""" # 建堆操作:堆化除叶节点以外的其他所有节点 for i inrange(len(nums) // 2 - 1, -1, -1): sift_down(nums, len(nums), i) # 从堆中提取最大元素,循环 n-1 轮 for i inrange(len(nums) - 1, 0, -1): # 交换根节点与最右叶节点(即交换首元素与尾元素) nums[0], nums[i] = nums[i], nums[0] # 以根节点为起点,从顶至底进行堆化 sift_down(nums, i, 0)
/* 堆的长度为 n ,从节点 i 开始,从顶至底堆化 */ funcsiftDown(nums *[]int, n, i int) { fortrue { // 判断节点 i, l, r 中值最大的节点,记为 ma l := 2*i + 1 r := 2*i + 2 ma := i if l < n && (*nums)[l] > (*nums)[ma] { ma = l } if r < n && (*nums)[r] > (*nums)[ma] { ma = r } // 若节点 i 最大或索引 l, r 越界,则无须继续堆化,跳出 if ma == i { break } // 交换两节点 (*nums)[i], (*nums)[ma] = (*nums)[ma], (*nums)[i] // 循环向下堆化 i = ma } }
/* 堆排序 */ funcheapSort(nums *[]int) { // 建堆操作:堆化除叶节点以外的其他所有节点 for i := len(*nums)/2 - 1; i >= 0; i-- { siftDown(nums, len(*nums), i) } // 从堆中提取最大元素,循环 n-1 轮 for i := len(*nums) - 1; i > 0; i-- { // 交换根节点与最右叶节点(即交换首元素与尾元素) (*nums)[0], (*nums)[i] = (*nums)[i], (*nums)[0] // 以根节点为起点,从顶至底进行堆化 siftDown(nums, i, 0) } }
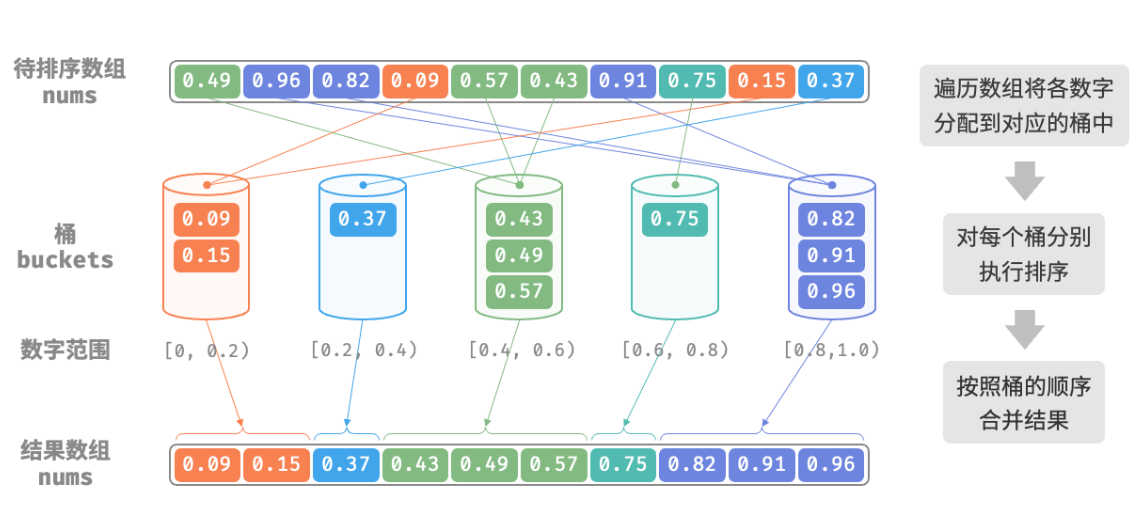
defbucket_sort(nums: list[float]): """桶排序""" # 初始化 k = n/2 个桶,预期向每个桶分配 2 个元素 k = len(nums) // 2 buckets = [[] for _ inrange(k)] # 1. 将数组元素分配到各个桶中 for num in nums: # 输入数据范围 [0, 1),使用 num * k 映射到索引范围 [0, k-1] i = int(num * k) # 将 num 添加进桶 i buckets[i].append(num) # 2. 对各个桶执行排序 for bucket in buckets: # 使用内置排序函数,也可以替换成其他排序算法 bucket.sort() # 3. 遍历桶合并结果 i = 0 for bucket in buckets: for num in bucket: nums[i] = num i += 1
/* 桶排序 */ funcbucketSort(nums []float64) { // 初始化 k = n/2 个桶,预期向每个桶分配 2 个元素 k := len(nums) / 2 buckets := make([][]float64, k) for i := 0; i < k; i++ { buckets[i] = make([]float64, 0) } // 1. 将数组元素分配到各个桶中 for _, num := range nums { // 输入数据范围 [0, 1),使用 num * k 映射到索引范围 [0, k-1] i := int(num * float64(k)) // 将 num 添加进桶 i buckets[i] = append(buckets[i], num) } // 2. 对各个桶执行排序 for i := 0; i < k; i++ { // 使用内置切片排序函数,也可以替换成其他排序算法 sort.Float64s(buckets[i]) } // 3. 遍历桶合并结果 i := 0 for _, bucket := range buckets { for _, num := range bucket { nums[i] = num i++ } } }
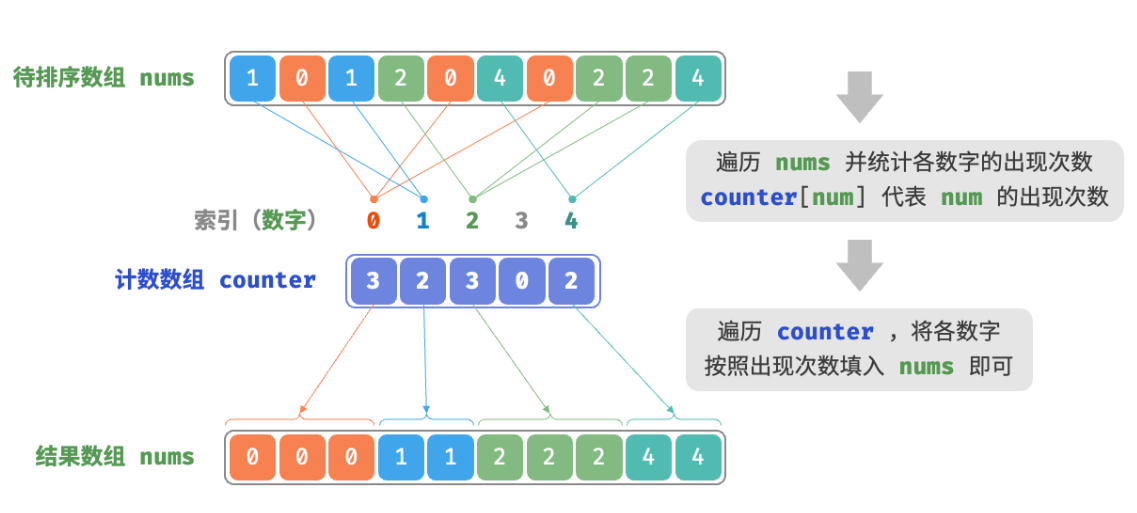
defcounting_sort_naive(nums: list[int]): """计数排序""" # 简单实现,无法用于排序对象 # 1. 统计数组最大元素 m m = 0 for num in nums: m = max(m, num) # 2. 统计各数字的出现次数 # counter[num] 代表 num 的出现次数 counter = [0] * (m + 1) for num in nums: counter[num] += 1 # 3. 遍历 counter ,将各元素填入原数组 nums i = 0 for num inrange(m + 1): for _ inrange(counter[num]): nums[i] = num i += 1
/* 计数排序 */ // 简单实现,无法用于排序对象 funccountingSortNaive(nums []int) { // 1. 统计数组最大元素 m m := 0 for _, num := range nums { if num > m { m = num } } // 2. 统计各数字的出现次数 // counter[num] 代表 num 的出现次数 counter := make([]int, m+1) for _, num := range nums { counter[num]++ } // 3. 遍历 counter ,将各元素填入原数组 nums for i, num := 0, 0; num < m+1; num++ { for j := 0; j < counter[num]; j++ { nums[i] = num i++ } } }
/* 获取元素 num 的第 k 位,其中 exp = 10^(k-1) */ funcdigit(num, exp int)int { // 传入 exp 而非 k 可以避免在此重复执行昂贵的次方计算 return (num / exp) % 10 }
/* 计数排序(根据 nums 第 k 位排序) */ funccountingSortDigit(nums []int, exp int) { // 十进制的位范围为 0~9 ,因此需要长度为 10 的桶 counter := make([]int, 10) n := len(nums) // 统计 0~9 各数字的出现次数 for i := 0; i < n; i++ { d := digit(nums[i], exp) // 获取 nums[i] 第 k 位,记为 d counter[d]++ // 统计数字 d 的出现次数 } // 求前缀和,将“出现个数”转换为“数组索引” for i := 1; i < 10; i++ { counter[i] += counter[i-1] } // 倒序遍历,根据桶内统计结果,将各元素填入 res res := make([]int, n) for i := n - 1; i >= 0; i-- { d := digit(nums[i], exp) j := counter[d] - 1// 获取 d 在数组中的索引 j res[j] = nums[i] // 将当前元素填入索引 j counter[d]-- // 将 d 的数量减 1 } // 使用结果覆盖原数组 nums for i := 0; i < n; i++ { nums[i] = res[i] } }
/* 基数排序 */ funcradixSort(nums []int) { // 获取数组的最大元素,用于判断最大位数 max := math.MinInt for _, num := range nums { if num > max { max = num } } // 按照从低位到高位的顺序遍历 for exp := 1; max >= exp; exp *= 10 { // 对数组元素的第 k 位执行计数排序 // k = 1 -> exp = 1 // k = 2 -> exp = 10 // 即 exp = 10^(k-1) countingSortDigit(nums, exp) } }
相较于计数排序,基数排序适用于数值范围较大的情况,但前提是数据必须可以表示为固定位数的格式,且位数不能过大。例如,浮点数不适合使用基数排序,因为其位数 k 过大,可能导致时间复杂度 O(nk)≫O(n^2) 。
**时间复杂度 O(nk)**:设数据量为 n、数据为 d 进制、最大位数为 k ,则对某一位执行计数排序使用 O(n+d) 时间,排序所有 k 位使用 O((n+d)k) 时间。通常情况下,d 和 k 都相对较小,时间复杂度趋向 O(n) 。
空间复杂度 O(n+d)、非原地排序:与计数排序相同,基数排序需要借助长度为 n 和 d 的数组 res 和 counter 。







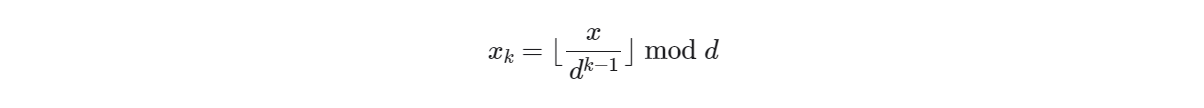
 微信
微信 支付宝
支付宝



